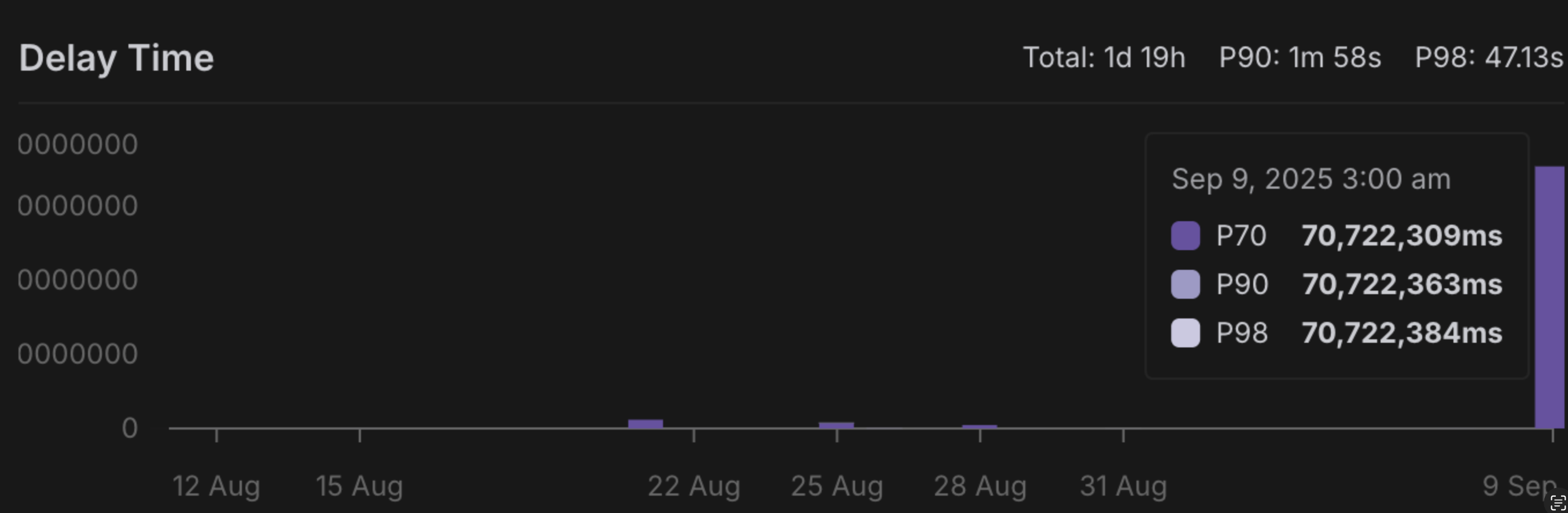
Extremely High Delay Time
 Date/Time: Sept 9, 2025
Date/Time: Sept 9, 2025 Observed Behavior:
Observed Behavior:At this timestamp, I noticed an extreme delay time of ~70,722,000 ms (≈ 19.6 hours) on my pod:
• P70: 70,722,309 ms
• P90: 70,722,363 ms
• P98: 70,722,384 ms
So this was cost 35$ and i don't understand why this happened and how to avoid this in future. The endpoint worked for months, and everything was OK, so i doubt it was related to my code.
https://api.runpod.ai/v2/ln9cqu2idn7f94/run
 Expected: Delay times should be within normal ranges. Timeout should work to not wait until whole limit is used.
Expected: Delay times should be within normal ranges. Timeout should work to not wait until whole limit is used. Request: Could someone please investigate if this was a system-level issue (e.g., frozen jobs, infrastructure hang, etc.)?
Request: Could someone please investigate if this was a system-level issue (e.g., frozen jobs, infrastructure hang, etc.)?