[Solved] SEO using routerWithQueryClient()
Hi all, using Tanstack Start for a small project and wanted to know if a situation is possible
Considerations:
- I'm using
- I can currently go to a dynamic route page with skeleton loader and then data loads
Requirement:
For SEO purposes I wish to add tags in the
Summarizing above: Is it possible to add seo tags in the
Thanks!
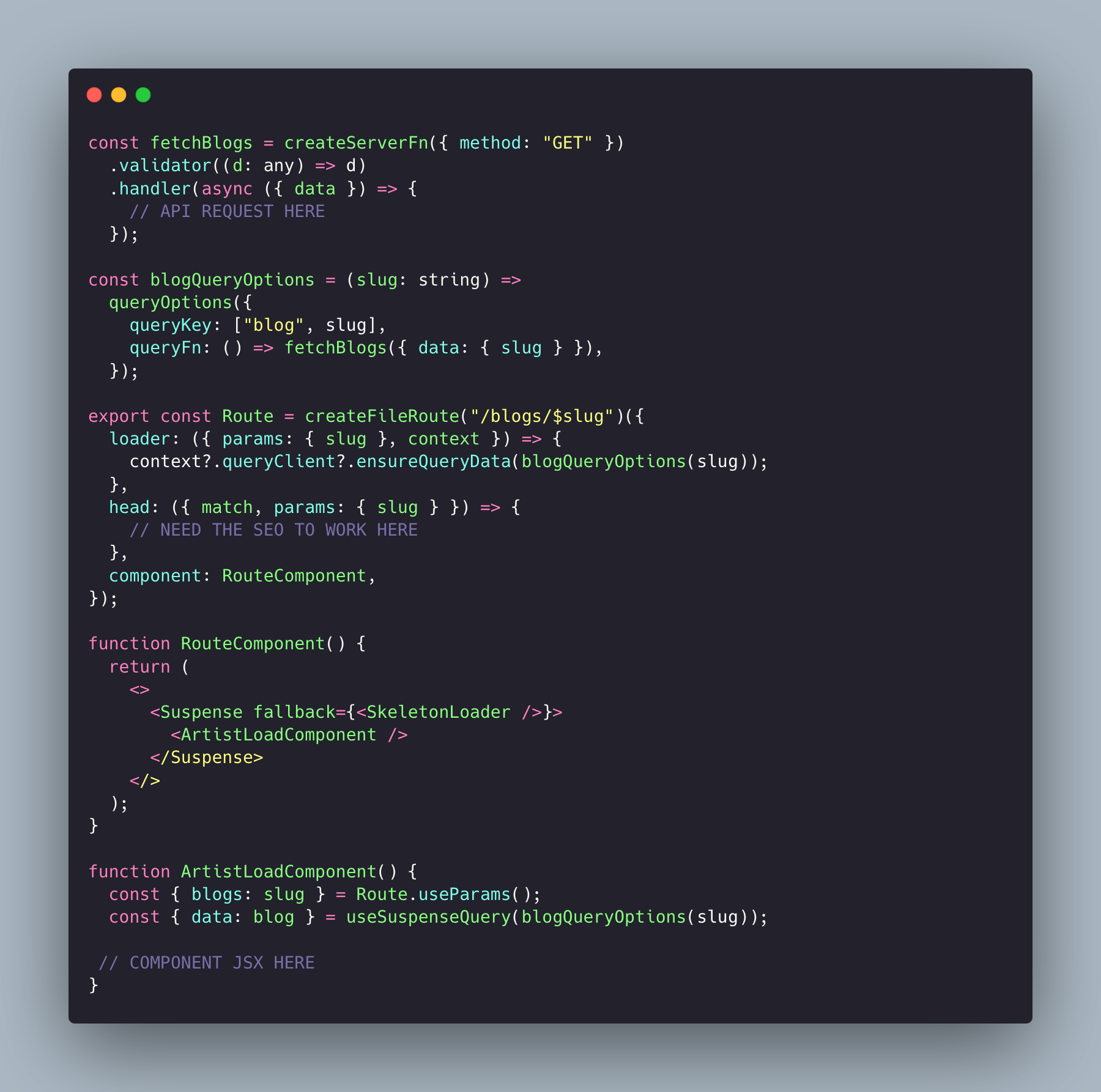
[code example attatched]
Considerations:
- I'm using
routerWithQueryClient()- I can currently go to a dynamic route page with skeleton loader and then data loads
Requirement:
For SEO purposes I wish to add tags in the
headcreateFileRouteSummarizing above: Is it possible to add seo tags in the
createFileRouteThanks!
[code example attatched]