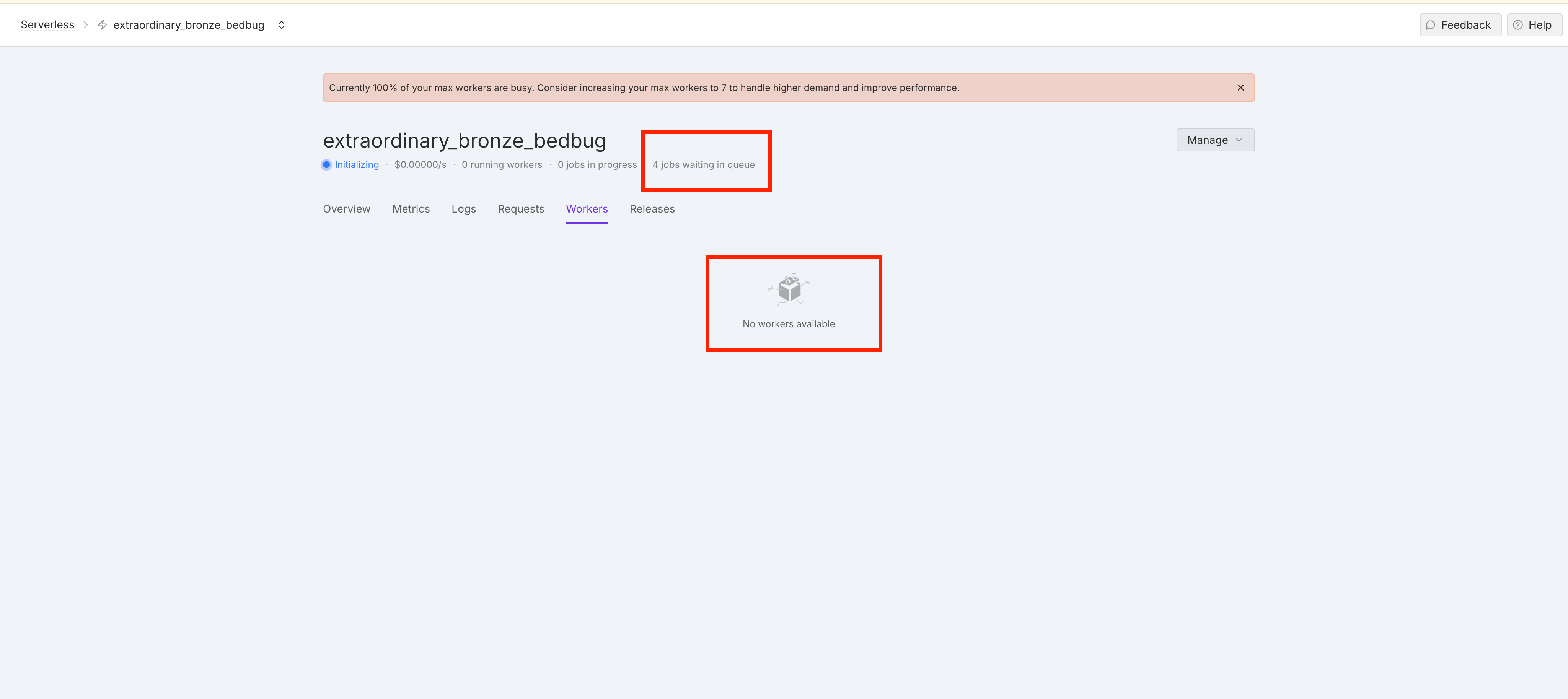
Serverless FAILING to add Workers
I have a queue-based endpoint created & i have 4 requests in the pipeline.
It's been over 30-40 mins and Serverless has failed to recruit any new H100 worker for me.
I don't have any data-centers (regions) specified.
It's been over 30-40 mins and Serverless has failed to recruit any new H100 worker for me.
I don't have any data-centers (regions) specified.