Remote Machine Learning full of errors when processing starts
I want to use my GPU to process my media. I started on my Windows 11 the machine learning container with CUDA image. Then I changed the settings in Immich to use this container as a machine learning server.
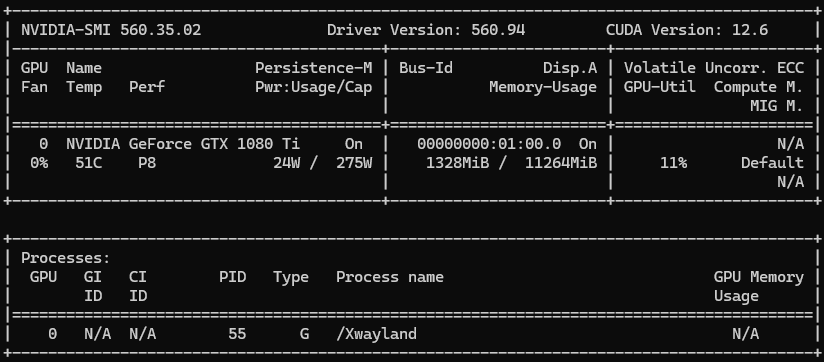
When I started queued jobs I saw that it could successfully connect to the remote machine learning server, but a lot of errors were logged.
I attached a screenshot when I run
Somebody knows what the problem is?
docker-compose.yml:
Logs:
When I started queued jobs I saw that it could successfully connect to the remote machine learning server, but a lot of errors were logged.
I attached a screenshot when I run
docker exec -it immich_machine_learning nvidia-smiSomebody knows what the problem is?
docker-compose.yml:
name: immich_remote_ml
services:
immich-machine-learning:
container_name: immich_machine_learning
image: altran1502/immich-machine-learning:v2.1.0-cuda
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities:
- gpu
volumes:
- model-cache:/cache
restart: always
ports:
- 3003:3003
volumes:
model-cache:Logs:
[10/21/25 12:21:37] INFO Starting gunicorn 23.0.0
[10/21/25 12:21:37] INFO Listening at: http://[::]:3003 (8)
2025-10-21 12:30:27.143106979 [E:onnxruntime:Default, cuda_call.cc:118 CudaCall] CUDNN failure 5000: CUDNN_STATUS_EXECUTION_FAILED ; GPU=0 ; hostname=b9f607173de1 ; file=/onnxruntime_src/onnxruntime/core/providers/cuda/nn/conv.cc ; line=455 ; expr=cudnnConvolutionForward(cudnn_handle, &alpha, s_.x_tensor, s_.x_data, s_.w_desc, s_.w_data, s_.conv_desc, s_.algo, workspace.get(), s_.workspace_bytes, &beta, s_.y_tensor, s_.y_data);
2025-10-21 12:30:27.143238491 [E:onnxruntime:, sequential_executor.cc:516 ExecuteKernel] Non-zero status code returned while running Conv node. Name:'/visual/conv1/Conv' Status Message: CUDNN failure 5000: CUDNN_STATUS_EXECUTION_FAILED ; GPU=0 ; hostname=b9f607173de1 ; file=/onnxruntime_src/onnxruntime/core/providers/cuda/nn/conv.cc ; line=455 ; expr=cudnnConvolutionForward(cudnn_handle, &alpha, s_.x_tensor, s_.x_data, s_.w_desc, s_.w_data, s_.conv_desc, s_.algo, workspace.get(), s_.workspace_bytes, &beta, s_.y_tensor, s_.y_data);
2025-10-21 12:30:27.145386284 [E:onnxruntime:Default, cuda_call.cc:118 CudaCall] CUDNN failure 5000: CUDNN_STATUS_EXECUTION_FAILED ; GPU=0 ; hostname=b9f607173de1 ; file=/onnxruntime_src/onnxruntime/core/providers/cuda/nn/conv.cc ; line=455 ; expr=cudnnConvolutionForward(cudnn_handle, &alpha, s_.x_tensor, s_.x_data, s_.w_desc, s_.w_data, s_.conv_desc, s_.algo, workspace.get(), s_.workspace_bytes, &beta, s_.y_tensor, s_.y_data);
2025-10-21 12:30:27.145452290 [E:onnxruntime:, sequential_executor.cc:516 ExecuteKernel] Non-zero status code returned while running Conv node. Name:'/visual/conv1/Conv' Status Message: CUDNN failure 5000: CUDNN_STATUS_EXECUTION_FAILED ; GPU=0 ; hostname=b9f607173de1 ; file=/onnxruntime_src/onnxruntime/core/providers/cuda/nn/conv.cc ; line=455 ; expr=cudnnConvolutionForward(cudnn_handle, &alpha, s_.x_tensor, s_.x_data, s_.w_desc, s_.w_data, s_.conv_desc, s_.algo, workspace.get(), s_.workspace_bytes, &beta, s_.y_tensor, s_.y_data);
[10/21/25 12:30:27] ERROR Exception in ASGI application