Idle period between LLM API call and tool calls
WorkflowsAgentTools
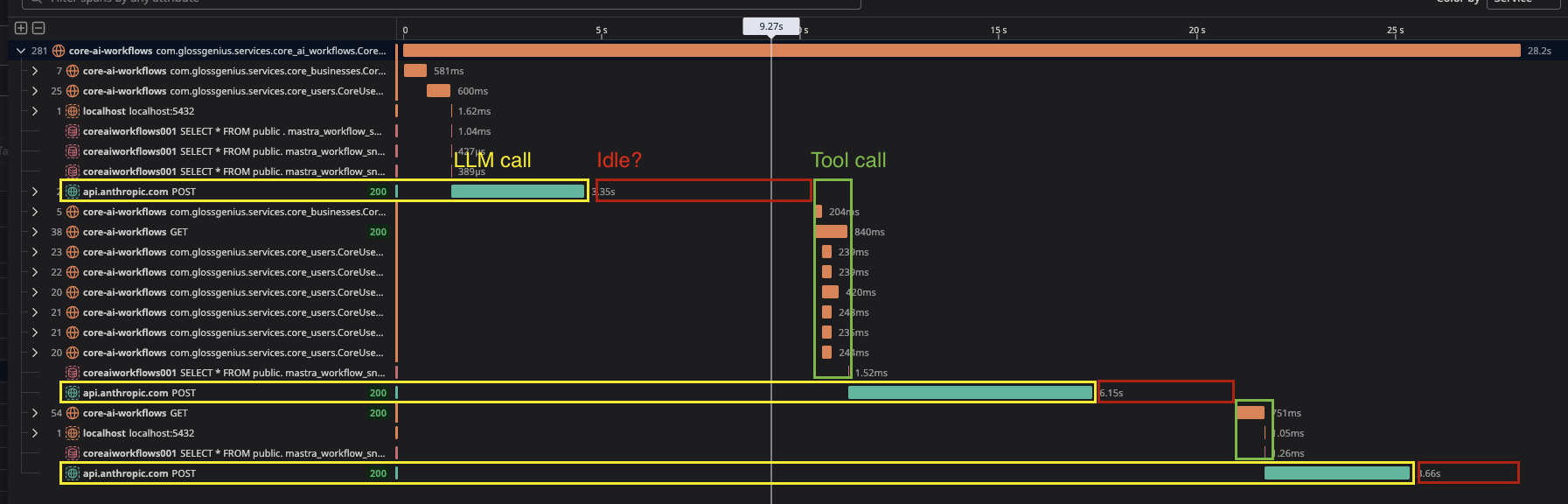
Hey all! I noticed something in Datadog recently. There seem to be big idle gaps between when the LLM API call returns and when the tools actually execute. In Langfuse, the total time of the model call + idle block corresponds to a
I'm just using baseline features without any fancy memory options. Could this be real or is the LLM span incorrect? How can I debug this?
My generations do feel slower than they should. I have a small context (5k tokens max), 2 rounds of tool calls and it's taking 28s on Sonnet 4. I see the same behavior with OpenAI models.
Thanks!
workflow step: 'llm-execution'I'm just using baseline features without any fancy memory options. Could this be real or is the LLM span incorrect? How can I debug this?
My generations do feel slower than they should. I have a small context (5k tokens max), 2 rounds of tool calls and it's taking 28s on Sonnet 4. I see the same behavior with OpenAI models.
Thanks!