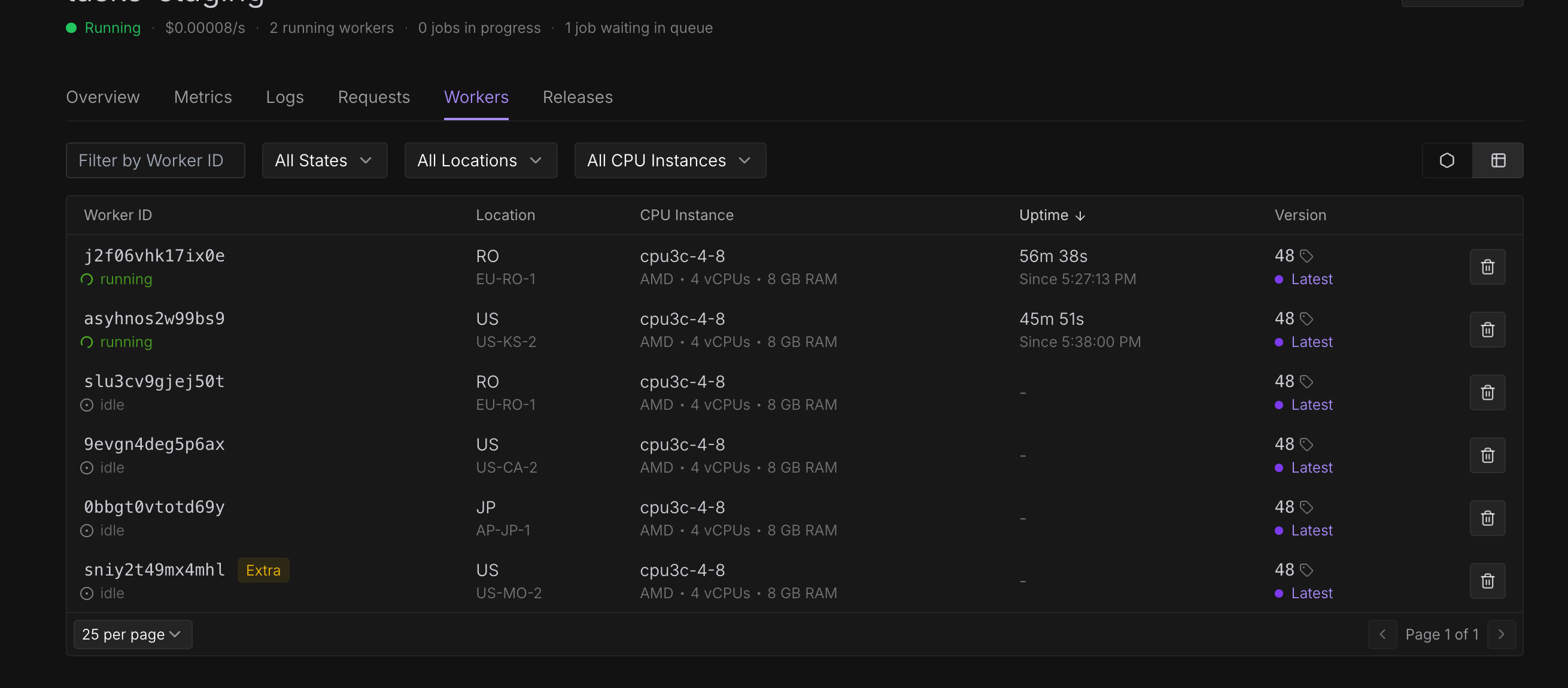
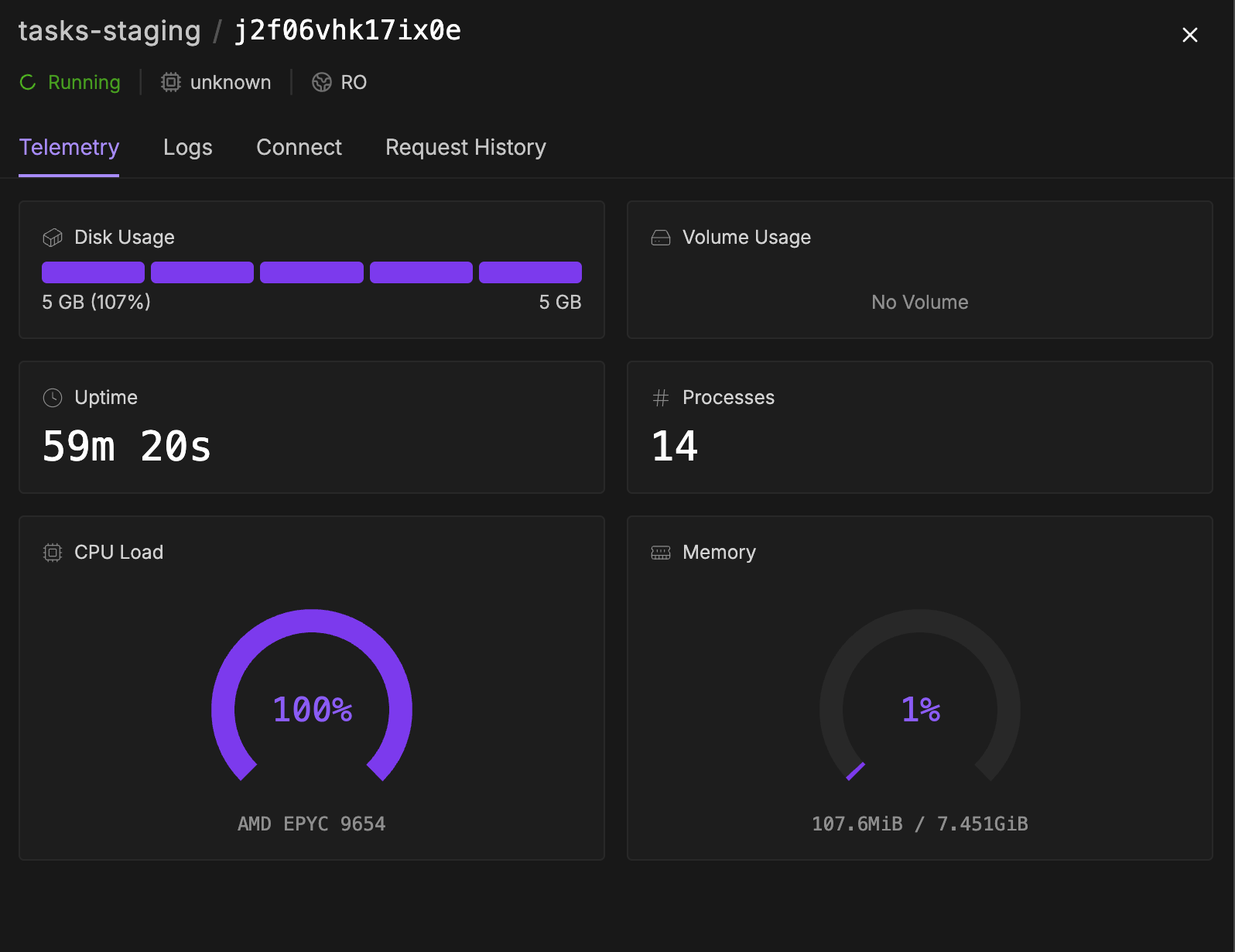
Runpod workers continuing to run after job has already failed.
As shown in the screenshot, two of my serverless workers are continuing to run, even though, as shown by the dashboard header, no jobs are currently in progress. What is also odd is my execution timeout is set to 1200 sec (20 min), which is far below the amount of time these workers have been running for. I did observe the following error in the worker logs:
perhaps this is an edge case related to the worker's system resources becoming completely saturated?
perhaps this is an edge case related to the worker's system resources becoming completely saturated?