cuda>=12.9 error
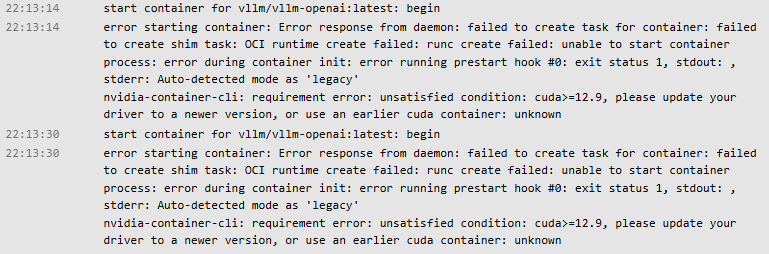
When deploying a pod on RunPod using an RTX 4090 GPU with the vllm/vllm-openai:latest container image, the container fails to start and enters a crash loop. The logs show the following error:
nvidia-container-cli: requirement error: unsatisfied condition: cuda>=12.9
This indicates that the vLLM image requires CUDA 12.9, but the underlying RunPod RTX 4090 nodes currently provide an older CUDA version (typically CUDA 12.1–12.4).
Because of this CUDA mismatch, the container cannot initialize, the model never loads, and although port 8000 appears "Ready", all API endpoints (e.g., /v1/models) return 404 because the server never actually started.
Root Cause:
The latest vLLM image requires a newer CUDA runtime (12.9+)
RunPod GPU nodes have not yet been updated to this CUDA version
Solution:
Use an older CUDA-compatible vLLM image (e.g., vllm-openai:cuda12.1)
Or switch to RunPod’s officially provided vLLM template that matches node CUDA drivers
nvidia-container-cli: requirement error: unsatisfied condition: cuda>=12.9
This indicates that the vLLM image requires CUDA 12.9, but the underlying RunPod RTX 4090 nodes currently provide an older CUDA version (typically CUDA 12.1–12.4).
Because of this CUDA mismatch, the container cannot initialize, the model never loads, and although port 8000 appears "Ready", all API endpoints (e.g., /v1/models) return 404 because the server never actually started.
Root Cause:
The latest vLLM image requires a newer CUDA runtime (12.9+)
RunPod GPU nodes have not yet been updated to this CUDA version
Solution:
Use an older CUDA-compatible vLLM image (e.g., vllm-openai:cuda12.1)
Or switch to RunPod’s officially provided vLLM template that matches node CUDA drivers