Serverless: nightly workers stuck “initializing” on SOME endpoints (delay time spikes)
I’m seeing a very consistent Serverless scaling issue for ~the last week, but IMPORTANT: this does NOT happen to all my endpoints — only to some of them. Other endpoints remain stable during the same time window.
Example affected endpoint ID: owufvdufc1h5x2
Time window (daily):
- 18:00–23:00 UTC
Symptoms (only on some endpoints, during that window):
- The endpoint often can’t maintain the required number of workers (sometimes it drops to 0)
- Workers remain in “initializing” for a long time
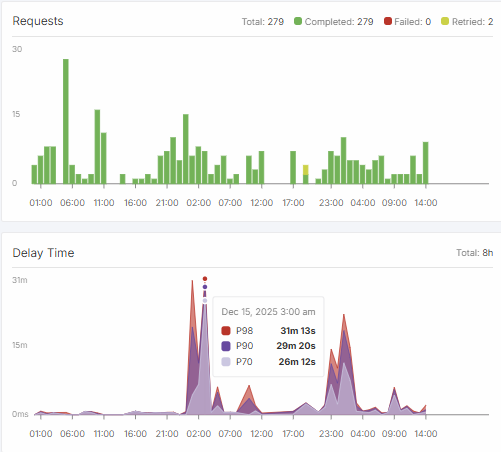
- “Delay time” jumps from ~1s to up to ~30 minutes at peak
Outside this window, everything works normally.
My worker is packaged in Docker and pulled from Docker Hub. I know “initializing” can include downloading the Docker image to a new worker, and requests arriving during initialization will be delayed.
Question: Can I find out the root cause of these nightly failures on only some endpoints? Any recommended fixes/settings (min workers, caching models, scaling config), and is there any specific log/request history I should collect from the Console Workers tab to help you investigate?
Example affected endpoint ID: owufvdufc1h5x2
Time window (daily):
- 18:00–23:00 UTC
Symptoms (only on some endpoints, during that window):
- The endpoint often can’t maintain the required number of workers (sometimes it drops to 0)
- Workers remain in “initializing” for a long time
- “Delay time” jumps from ~1s to up to ~30 minutes at peak
Outside this window, everything works normally.
My worker is packaged in Docker and pulled from Docker Hub. I know “initializing” can include downloading the Docker image to a new worker, and requests arriving during initialization will be delayed.
Question: Can I find out the root cause of these nightly failures on only some endpoints? Any recommended fixes/settings (min workers, caching models, scaling config), and is there any specific log/request history I should collect from the Console Workers tab to help you investigate?