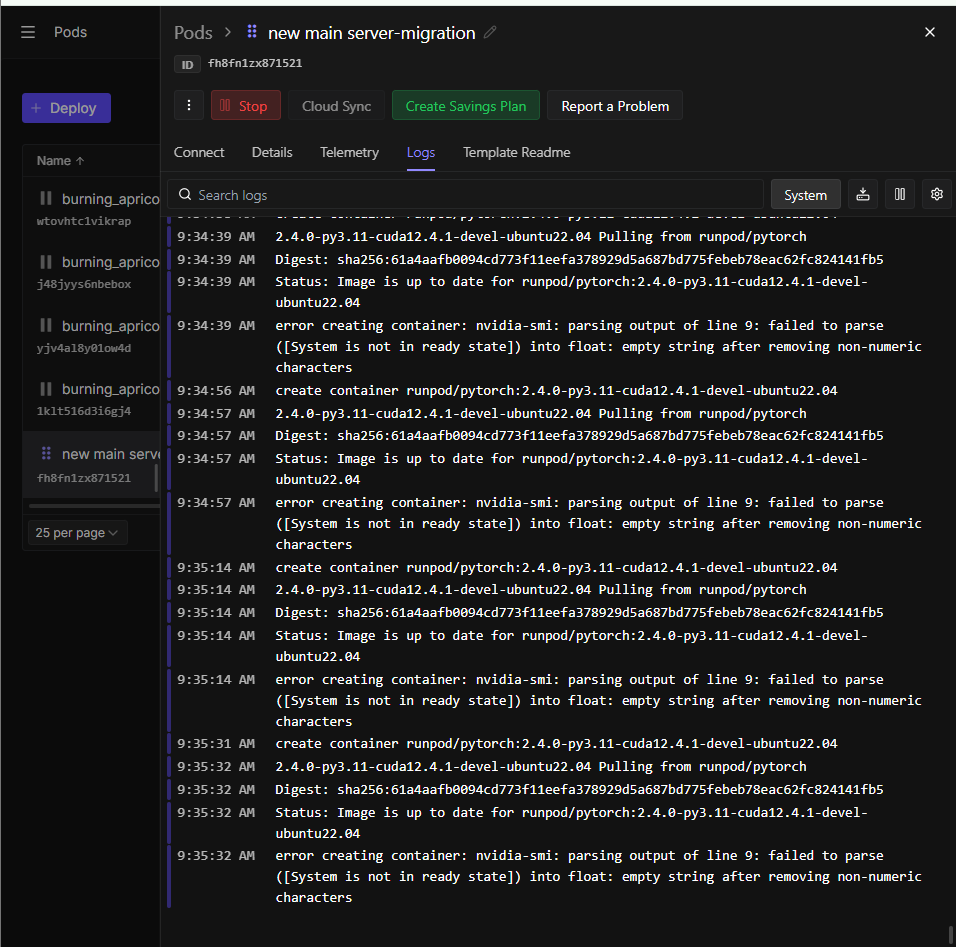
Pod stuck in boot loop - nvidia-smi "System is not in ready state" A40 Secure Cloud
My pod (fh8fn1zx871521) is stuck in a crash loop and cannot start. The error is:
error creating container: nvidia-smi: parsing output of line 9: failed to parse ([System is not in ready state]) into float: empty string after removing non-numeric characters
The pod has auto-migrated multiple times (pod name shows migration-migration-migration) but keeps landing on unhealthy nodes with the same error.
I have data on the container disk with no network volume attached, so I cannot create a CPU pod to recover files. The dashboard shows critical error detected with maintenance scheduled 3/9-3/11.
I've also submitted a support ticket but wanted to post here for visibility. Can someone help migrate this pod to a healthy node or help me recover my data before the maintenance window?
Pod ID: fh8fn1zx871521
GPU: A40
Cloud: Secure Cloud
Image: runpod/pytorch:2.4.0-py3.11-cuda12.4.1-devel-ubuntu22.04
error creating container: nvidia-smi: parsing output of line 9: failed to parse ([System is not in ready state]) into float: empty string after removing non-numeric characters
The pod has auto-migrated multiple times (pod name shows migration-migration-migration) but keeps landing on unhealthy nodes with the same error.
I have data on the container disk with no network volume attached, so I cannot create a CPU pod to recover files. The dashboard shows critical error detected with maintenance scheduled 3/9-3/11.
I've also submitted a support ticket but wanted to post here for visibility. Can someone help migrate this pod to a healthy node or help me recover my data before the maintenance window?
Pod ID: fh8fn1zx871521
GPU: A40
Cloud: Secure Cloud
Image: runpod/pytorch:2.4.0-py3.11-cuda12.4.1-devel-ubuntu22.04