crawlee-js
apify-platform
crawlee-python
💻hire-freelancers
🚀actor-promotion
💫feature-request
💻devs-and-apify
🗣general-chat
🎁giveaways
programming-memes
🌐apify-announcements
🕷crawlee-announcements
👥community
using Langchain ApifyWrapper
Effective TripAdvisor scraping
Cannot run this public Actor with Creator plan
apify/instagram-reel-scraper. I got this error You cannot run this public Actor. Your current plan does not support running public Actors..
Anyone tell me why and how to fix?...Can I get Google reviews only for a list of preselected businesses?
Loading files along with HTML-scraped content via LangChain's ApifyDatasetLoader
Apify Actor Not Loading (Day 2)
We have disabled the system which sent notifications about finished runs

Most Recent Tweets Scraper
web.harvester/twitter-scraper was depreciated which is very disappointing since it did exactly what I needed which was to take in a list of handles and return all tweets (including images) from those handles for the past X days.
I am trying to find a reliable alternative which can accomplish the same task. I was looking at quacker/twitter-scraper, but it cannot pull most recent and both the actors it suggests for that are broken/depreciated....How do I get a run's input after run is complete?
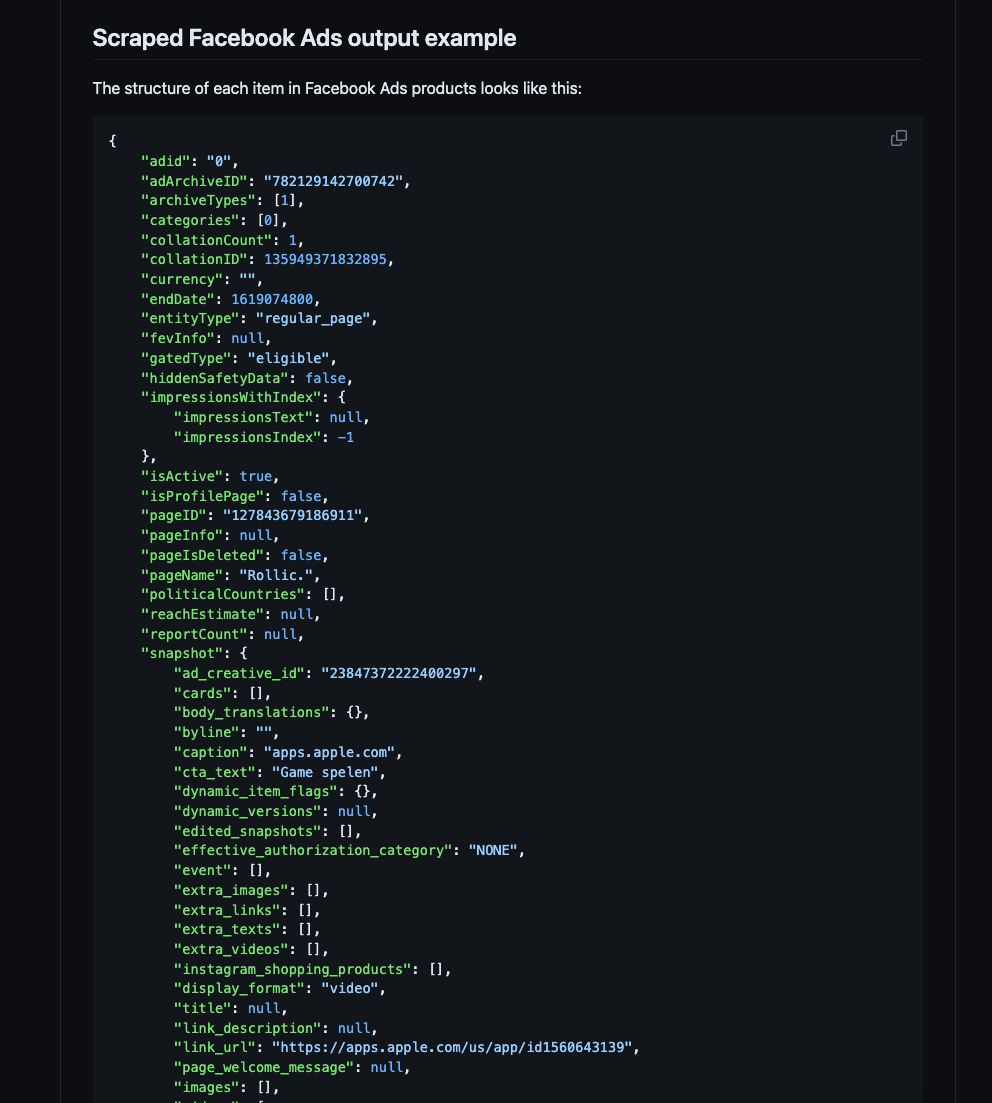
Facebook Ads Details API
Actors for a specific GPT
Passing the output of an actor to another and run it Python API
Run Queue
limit dataset items
Apify CLI question
Error: File name cannot exceed 100 characters
may I ask what does it mean? 🫣🤔 Like I have file that contains too many characters? I look at my files and I don't see any that has more then 100 characters 🤔
thank you for the answer 🫶🤗...Daily WebScraper Help
Proxies
Subscribing to changelog using RSS?
https://cms.apify.com/api/change-log-items?pagination[limit]=-1&populate=deep, but I'm not sure what cms.apify.com is and whether it's able to give me a good old RSS or Atom feed....
Suggestion: Notify me only when my actor fails

Not getting right content when crawling Levis website