crawlee-js
apify-platform
crawlee-python
💻hire-freelancers
🚀actor-promotion
💫feature-request
💻devs-and-apify
🗣general-chat
🎁giveaways
programming-memes
🌐apify-announcements
🕷crawlee-announcements
👥community
Cannot Extract Data
How to parse out results in Langchain ApifyDatasetLoader
nodemon causing my server to restart, on every crawl, causing it to error out
create new
Access "mantained by community" Actors source code
[Incorrect Types] Apify JS Client

Apify Proxies Help
How does apify tiktok scraper decide which videos to scrape?
Actor run all results

Is there any way to set cookies before pupeteer run?
page.setCookie() but its only avalibale in handler ~
Is there any way I can setup it in here? so I dont have to go through a default handler just to set a cookie?
```js...Help with pricing on Ai Product Matcher
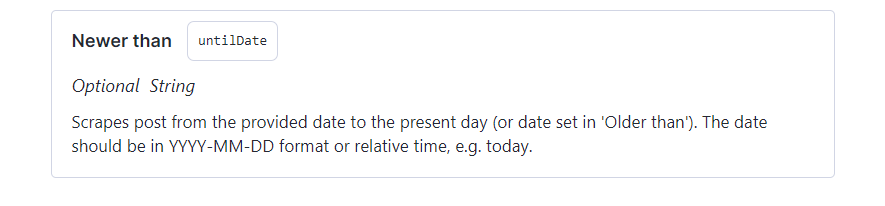
Instagram scraper - set date range.
Bulk SEO Scraper
Function isn't running when posted in api fy
Reconstructing clickable URLs from FB comment scraper output
Limiting Number of Concurrent Agents?
Mix Cheerio and Playwright same crawler
Is it possible to queue Actors execution?
judgereini