crawlee-js
apify-platform
crawlee-python
💻hire-freelancers
🚀actor-promotion
💫feature-request
💻devs-and-apify
🗣general-chat
🎁giveaways
programming-memes
🌐apify-announcements
🕷crawlee-announcements
👥community
Google Sheets Import & Export Actor

(maybe) Bug
enum with empty array:
```json
...
"kind": {"title": "Type", "type":"string", "description": "", "enum": []},...
Change Price after publish

TypeError: __init__() got an unexpected keyword argument 'follow_redirects'
httpx to 0.24 but apify client support 0.23
```python
APPIFY_CLIENT = ApifyClient(config('APIFY_CLIENT_TOKEN'))
File "/usr/share/pyshared/venv/airflow/lib/python3.8/site-packages/apify_client/client.py", line 126, in init
self.http_client = _HTTPClient(...How can I set actor timeout?
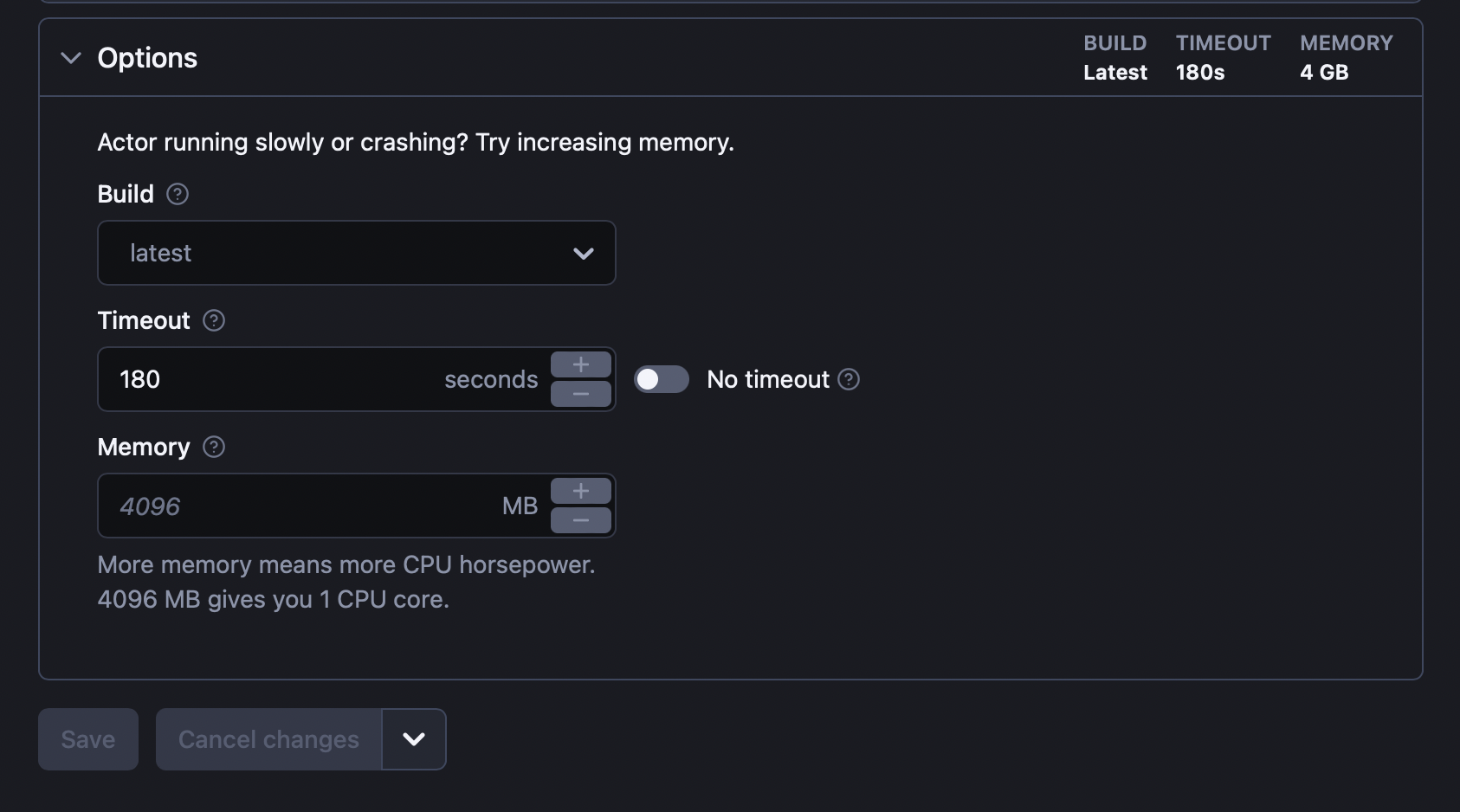
I am trying to use this crawler
Bug when using Apify.utils.requestAsBrowser: process seems to crash on timeout from the apify proxy

Playwright URL Parameter
Crawler with playwright doesn't stop

Upwork scraper is not scraping based on category
Google maps scraping based on search words and multiple city's.
Actor Privacy Policy?
Search unavailable on twitter?
crawler stops when there are still pending requests

How to have multiple crawler on the same repo ?
Twitter scraping: retrieving all replies to a Tweet

Zillow Terms of Use Violation?
Accessing Apify's Free Trial Period for Actors: Issue with Upgrading to Higher Plan
