Paying for H100 SXM but got an A100
nvidia-smi shows that I got an A100.
Unless I'm missing something, it looks like I'm not getting what I'm paying for....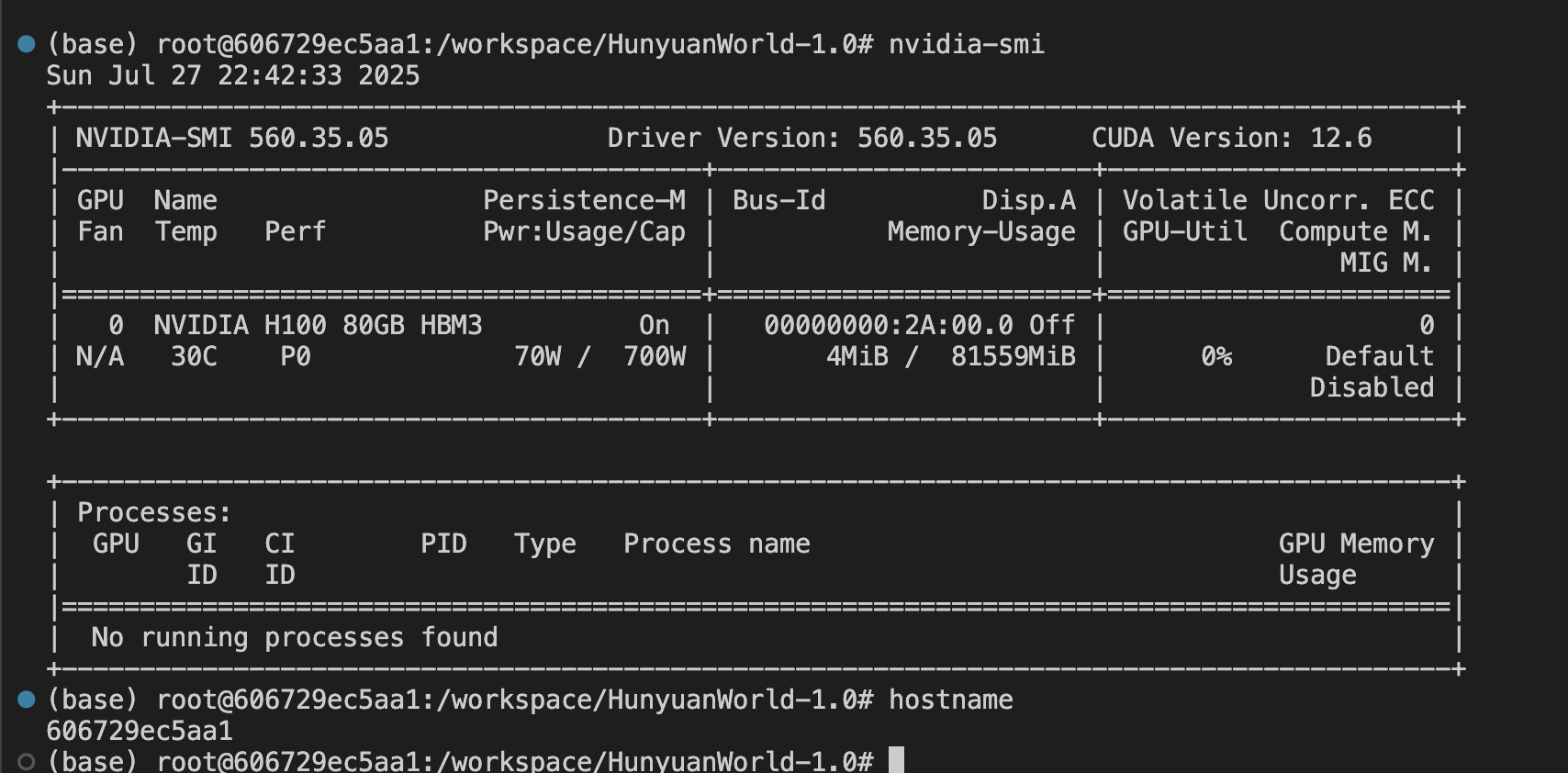
Degraded performance on EU datacenters when using ComfyUI
Issue with Texas pods - very low bandwidth
Raised a request for increase in A100 SXM Pods. How long would it take for approval?
My on-demand CPU Pod has been running 24/7 ...
Container not running error
ComfyUI webpage is taking lot of time to load. The services come up fine, in expected time.
ComfyUI is not loading
No root on pod. Cannot write to workspace.
slow network speed on EUR-IS-1
Unstable pod socket connection
"error creating container: nvidia-smi: parsing output of line 0: failed to"
Missing 12.9 cuda version in Create pod API
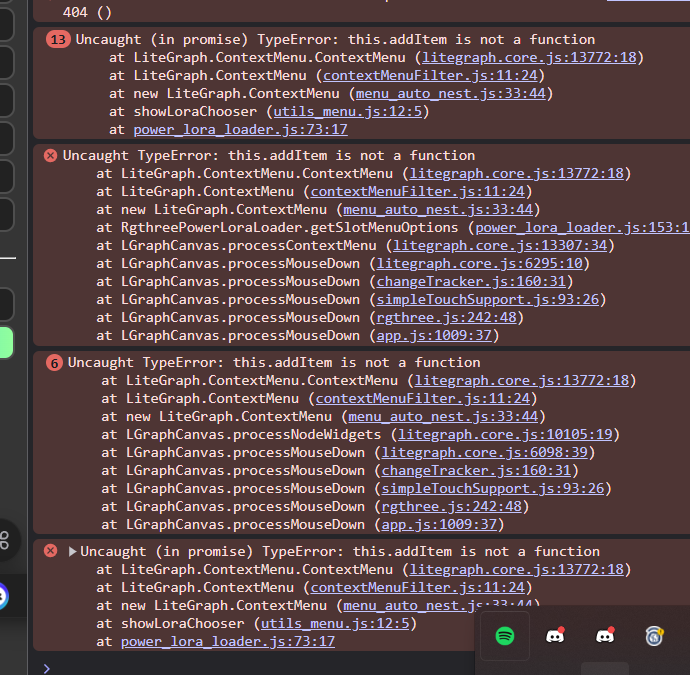
Lora Loader Node
Disk quota exceeded error hours after resizing
Help me how to install models into ComfyUi on runpod pls and ty
Is it possible to setup ZeroTier on a pod or serverless
COLMAP in custom docker template doesn't use CUDA/GPU
My public pod template is not visible to others in the explore section
CUDA 11.8 Seems unavailable in templates