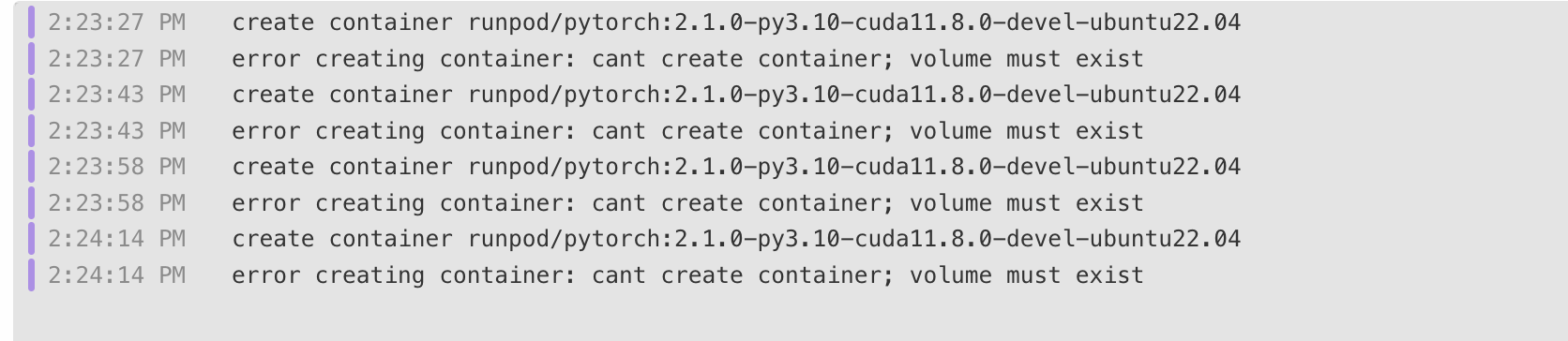
Pod with B200 wont start
When starting pod with B200 in RO datacenter (only place where B200 is available) I get following error:
Problem started recently. It worked few hours ago...
error creating container: nvidia-smi: parsing output of line 0: failed to parse (pcie.link.gen.max) into int: strconv.Atoi: parsing "": invalid syntax
error creating container: nvidia-smi: parsing output of line 0: failed to parse (pcie.link.gen.max) into int: strconv.Atoi: parsing "": invalid syntax
EUR-IS-1 pod with comfyUI, manager and pytorch 2.4 doesn't deploy
Initialization script doesn't seem to work it's been one hour trying...
Extreme slow speed when using ssh with network storage
Hello support, when i am using ssh today, i get extreme slow speed on every command (including ls or tab), and response also very slow.
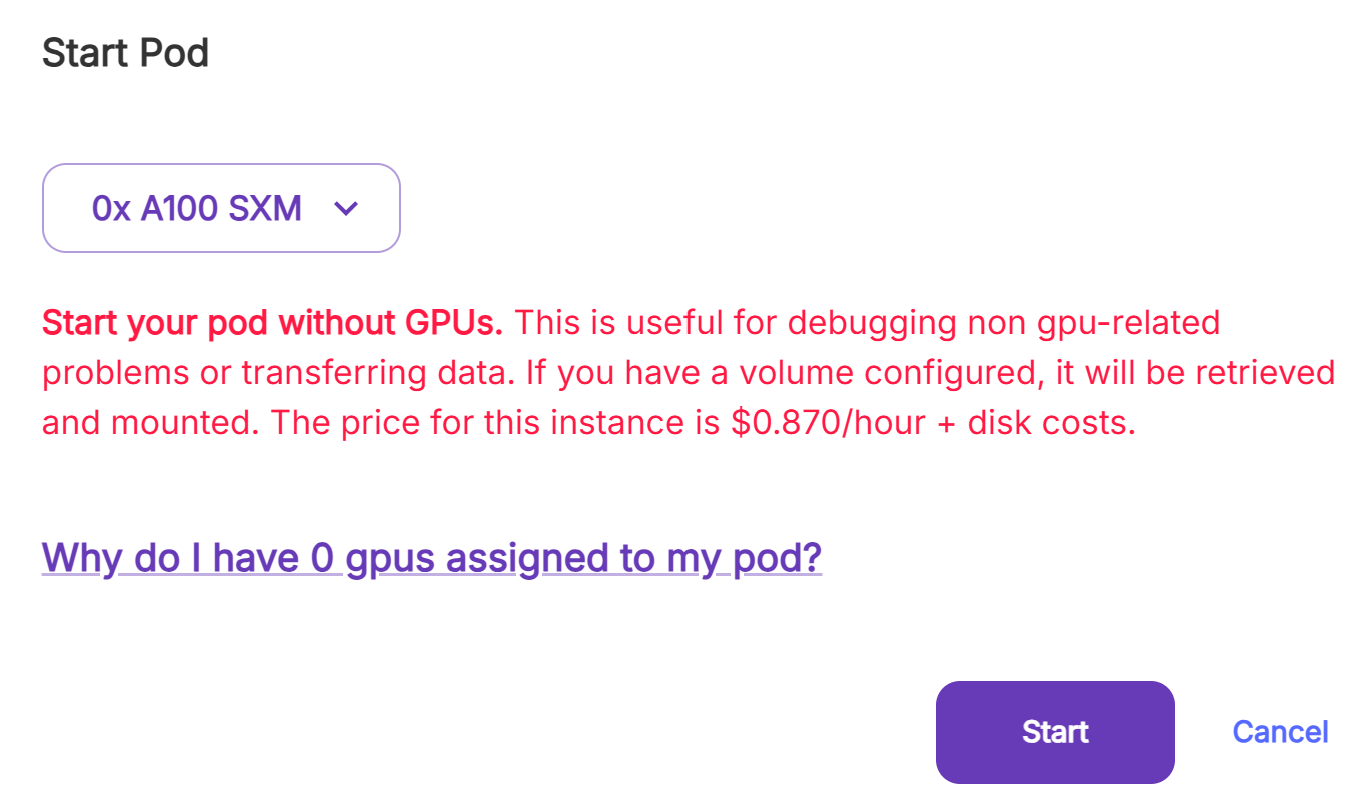
"Start your pod without GPUs" warning
My pods were working fine for the past couple of days and even earlier today but when I try to start one of them now it gives me that error. All my pods are "On-Demand". Does anyone know why this is happening and how I can fix it?
Solution:
Not sure what happened but it seems to be fixed now. Weird
connection to the pod doesn't work
When i run a pod, it runs normally, and the jupytor notebook runs as well. but If want to another porn, its grey screen
Slow startup times
Has anyone experienced really variable startup times? Loading comfyui today took 45+ minutes when it usually takes 1-2 minutes.
Also, jupyterlab in general has been laggy / not responsive. Yesterday was working just fine, so not sure if that's just me....
persistent volume sets permissions to 666
setting the persistent directory as /root sets the directory permissions to 666, and changig it with chmod does not help, this makes me unable to use ssh or git on the server, as well as prevent me from connecting without a password
504: Gateway time-out when long session
Hey, I have created an API that take a long times to answer the request (2 mins) and the api return a zip file.
Often, when I use the proxy to access the api, I have a 504: Gateway time-out error. I'm using a docker image.
How can I fix this issue (I think I have to add a longer timeout on the proxy server that you use)...
CUDA 12.8 Serverless fails
Hey so I just tried pushing a serverless worker for WAN 2.1 Running on cuda 12.8 however it seems to fail tests
```
Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running hook #0: error running hook: exit status 1, stdout: , stderr: Auto-detected mode as 'legacy' nvidia-container-cli: requirement error: unsatisfied condition: cuda>=12.8, please update your driver to a newer version, or use an earlier cuda container: unknown...
Can't boot the pod?
Just rented 3x 4090's, with the 2.8 pytorch template. when i check the logs, I see it can't boot due to some nvidia driver issue?
```bash
start container for runpod/pytorch:2.8.0-py3.11-cuda12.8.1-cudnn-devel-ubuntu22.04: begin
error starting container: Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running prestart hook #0: exit status 1, stdout: , stderr: Auto-detected mode as 'legacy'
nvidia-container-cli: requirement error: unsatisfied condition: cuda>=12.8, please update your driver to a newer version, or use an earlier cuda container: unknown...
AMD Pods won’t boot?
Hey, the AMD MI300X pods on RunPod are not working. Whenever I try to create a pod, no matter what region, it just stays stuck installed forever. This is agnostic of the container image. I have tested this on ROCm 5.7 as well as ROCm 6.1. I think there is something wrong here. Can anyone take a look and let me know?
More availability for CUDA 12.8 in EU-RO-1
Hey is there any plans on adding more Cuda 12.8 compatible pods to EU-RO-1. Afaik it's quite heavily used as it generally has good availability but seems to lack cuda 12.8.
[QUESTION] Best method for remote pod start/stop (CLI vs API v2)?
Hi all — I’m building an external controller to automate pod usage (start/stop pods remotely).
Can someone please confirm: what is currently the most reliable method to do this?
- CLI (runpodctl)?
- API v2?
- Or another recommended method? ...
Can someone please confirm: what is currently the most reliable method to do this?
- CLI (runpodctl)?
- API v2?
- Or another recommended method? ...
Are there any ways to use NCU(Nsight Compute)?
I need to launch a Pod in privileged mode to use NVIDIA Nsight Compute (ncu) for GPU profiling.
I have confirmed that the CLI tool I am using, runpodctl, does not have an option to set the --privileged flag for a container. The --args flag only overrides the container's CMD, it does not pass arguments to the Docker daemon.
Could you please let me know the official procedure to launch a Pod with privileged permissions? This is a critical requirement for my project....
CUDA 10.2 and pytorch 1.7.1 support needed
I have to deploy a pod for running wav2lip project that uses cuda 10.2 and pytorch 1.7.1
initially started with RTX 2000 ADA
got this error when running the project:...
Error when using 'nvidia-smi' on pod, 'Failed to initialize NVML: Unknown Error'
Hello. I am training ASR model on GPU pod, and as the title says, error started occurring.
I know this is a well-known issue and I know it needs to be fixed on the host server.
The pod information that the above issue occurred on is as follows....
Missing files
My pod restarted and wiped my entire /workspace directory. I had crucial scripts and files there that weren't backed up elsewhere. Is there a snapshot or backup you can restore?