How to load url data into Neptune?
I am trying to load a small dataset into Neptune and it seems to always error.
I tried
g.io("<file path>").
with(IO.reader, IO.graphson).
read().iterate()
And it says
"detailedMessage": "Failed to interpret Gremlin query: Query parsing failed at line 3, character position at 9, error message : token recognition error at: 'IO'",
So I tried without the IO
"detailedMessage": "Failed to interpret Gremlin query: IO request has to be a URL",
I tried to url manually and it downloads and works, so I know it is visible to Neptune, but I cannot get it to load.
I tried
g.io("<file path>").
with(IO.reader, IO.graphson).
read().iterate()
And it says
"detailedMessage": "Failed to interpret Gremlin query: Query parsing failed at line 3, character position at 9, error message : token recognition error at: 'IO'",
So I tried without the IO
"detailedMessage": "Failed to interpret Gremlin query: IO request has to be a URL",
I tried to url manually and it downloads and works, so I know it is visible to Neptune, but I cannot get it to load.
Solution
To add to what Kelvin is saying, Neptune can only access other instances that are within the same VPC. It cannot reach the Internet. If you need for it to access a public-facing URL, then you'll need to deploy a NAT gateway within the same VPC as Neptune and supply the proper routing within the VPC to allow Neptune to reach the Internet. This blog discusses it for the purpose of SPARQL Federated Queries being able to reach public SPARQL endpoints: https://aws.amazon.com/blogs/database/benefitting-from-sparql-1-1-federated-queries-with-amazon-neptune/
The concept also holds true from Gremlin
The concept also holds true from Gremlin
io()Amazon Web Services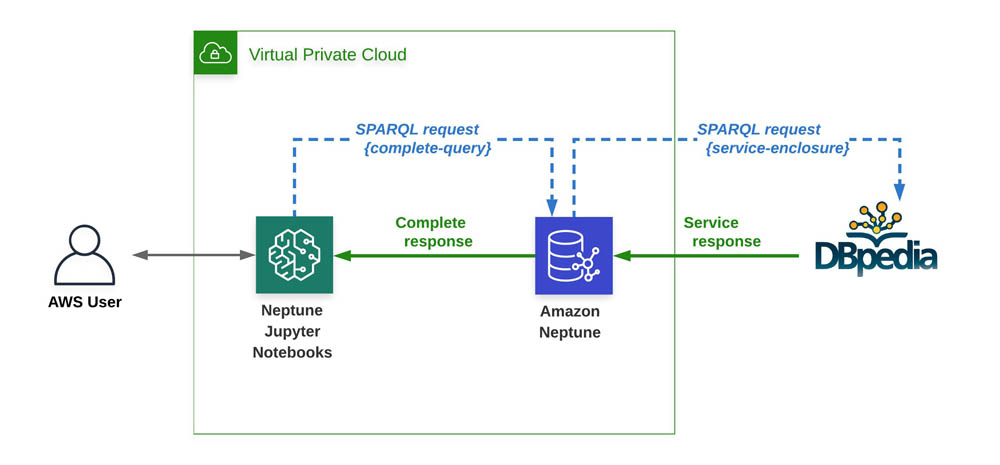
In this post, I show you how to use SPARQL 1.1 Federated Query in Neptune to get data about soccer teams in the UK from an external dataset, DBpedia (a well-known public dataset of Wikipedia data). Using the DBpedia publicly accessible SPARQL endpoint, I link the data from DBpedia to data that I add to the Neptune cluster.