Does async generator allow a worker to take off multiple jobs? Concurrency Modifier?
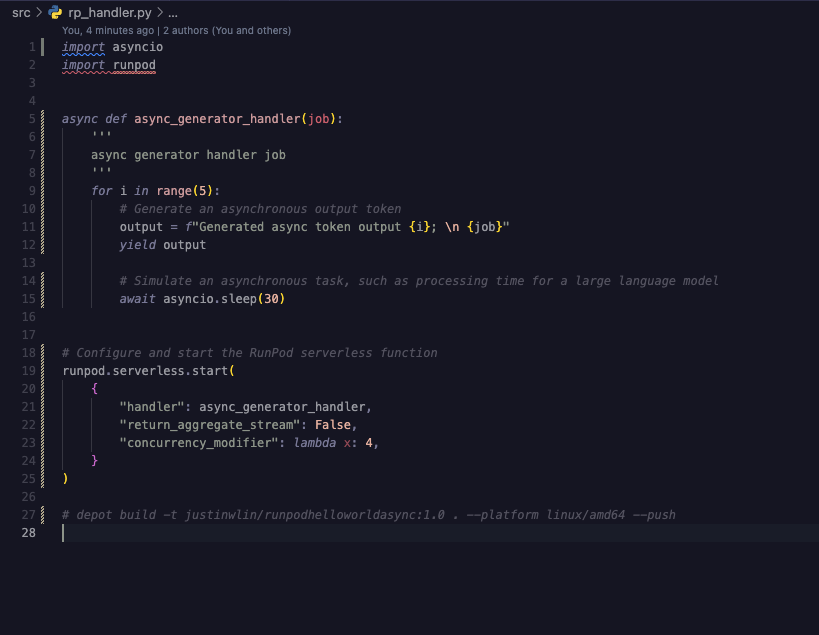
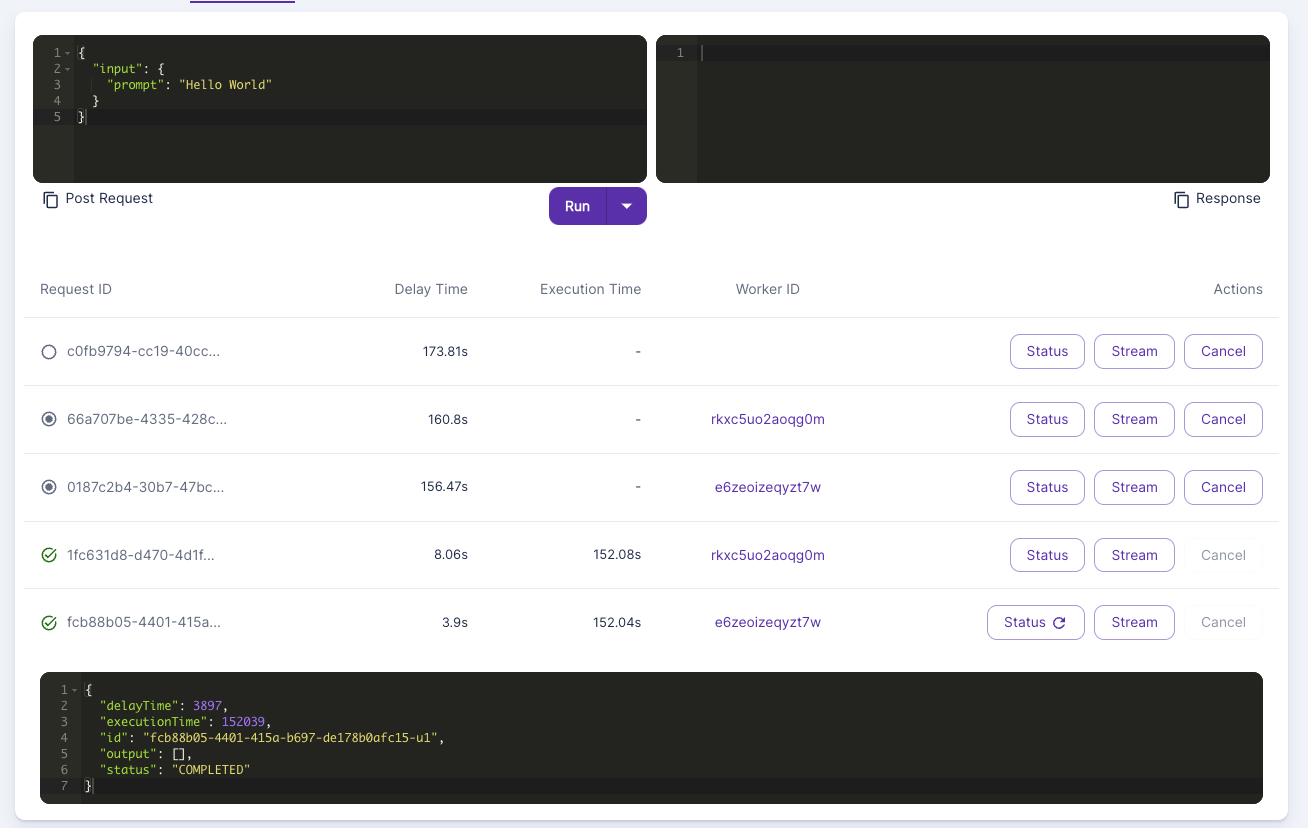
I was reading the runpod docs, and I saw the below. But does an async generator_handler, mean that if I sent 5 jobs for example that one worker will just keep on picking up new jobs?
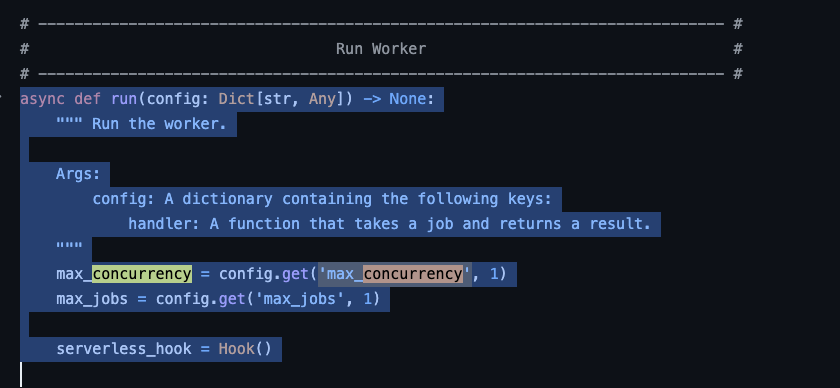
I also tried to add the:
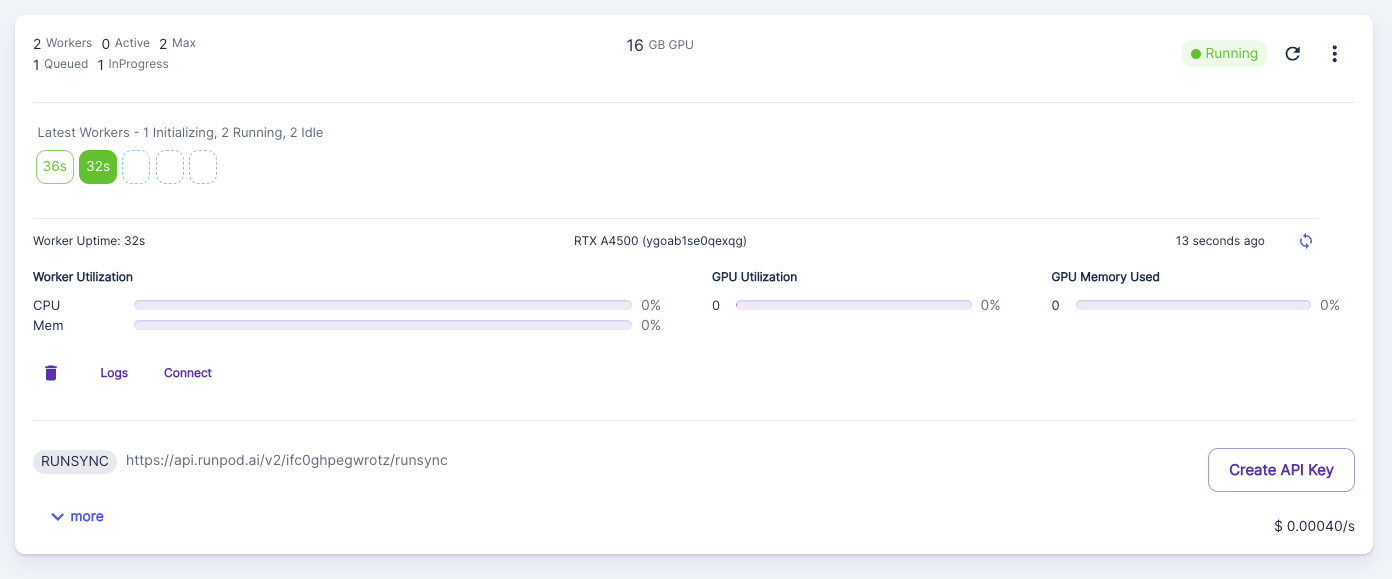
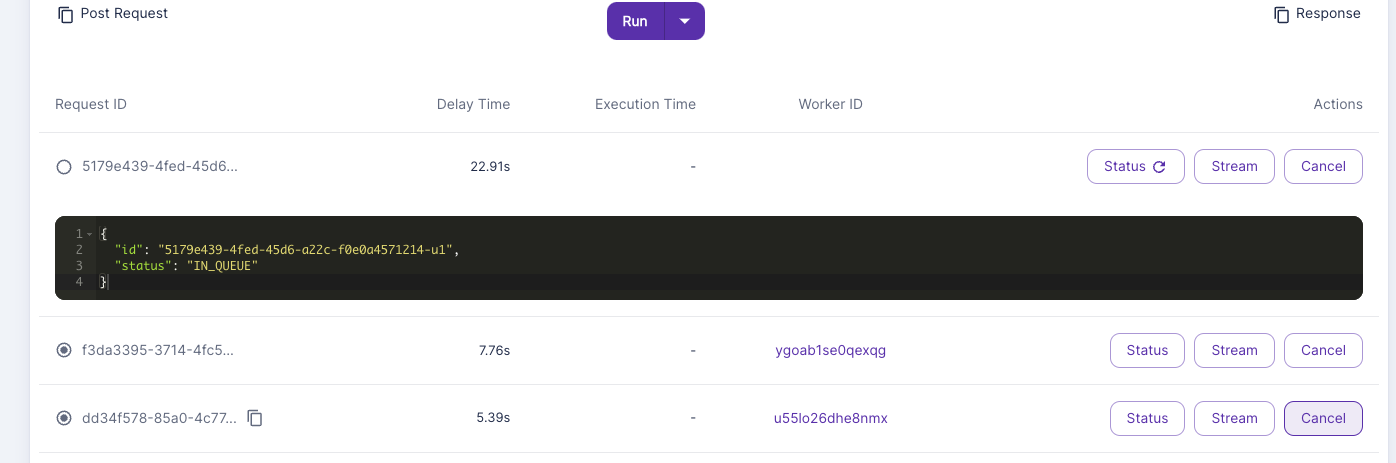
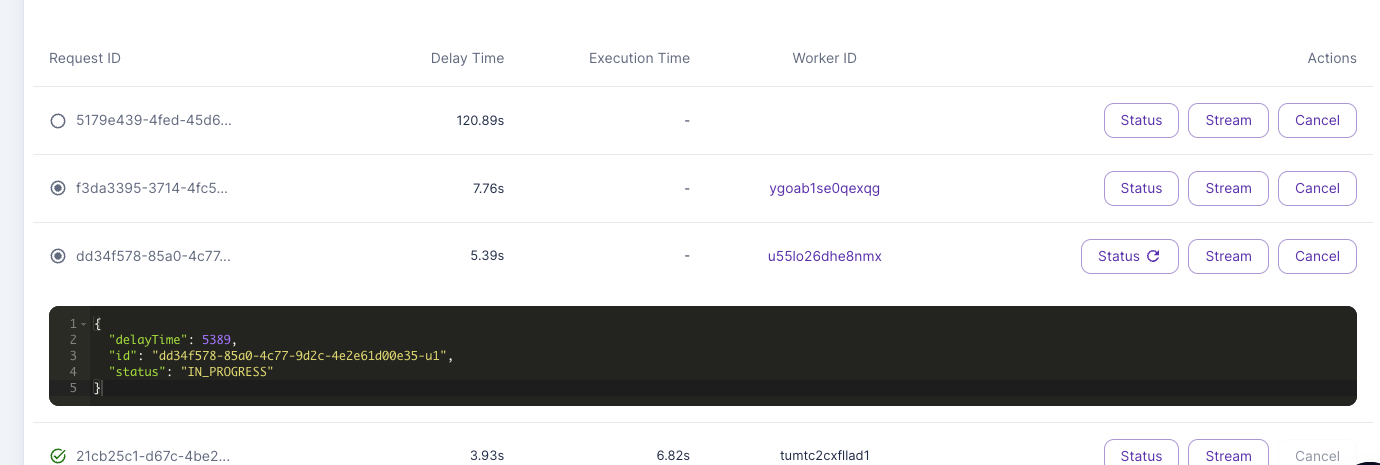
But if I queued up 10 jobs, it would first max out the workers, and just have jobs sitting in queue, rather than each worker picking up to the max number of concurrency modifiers?
https://docs.runpod.io/serverless/workers/handlers/handler-async
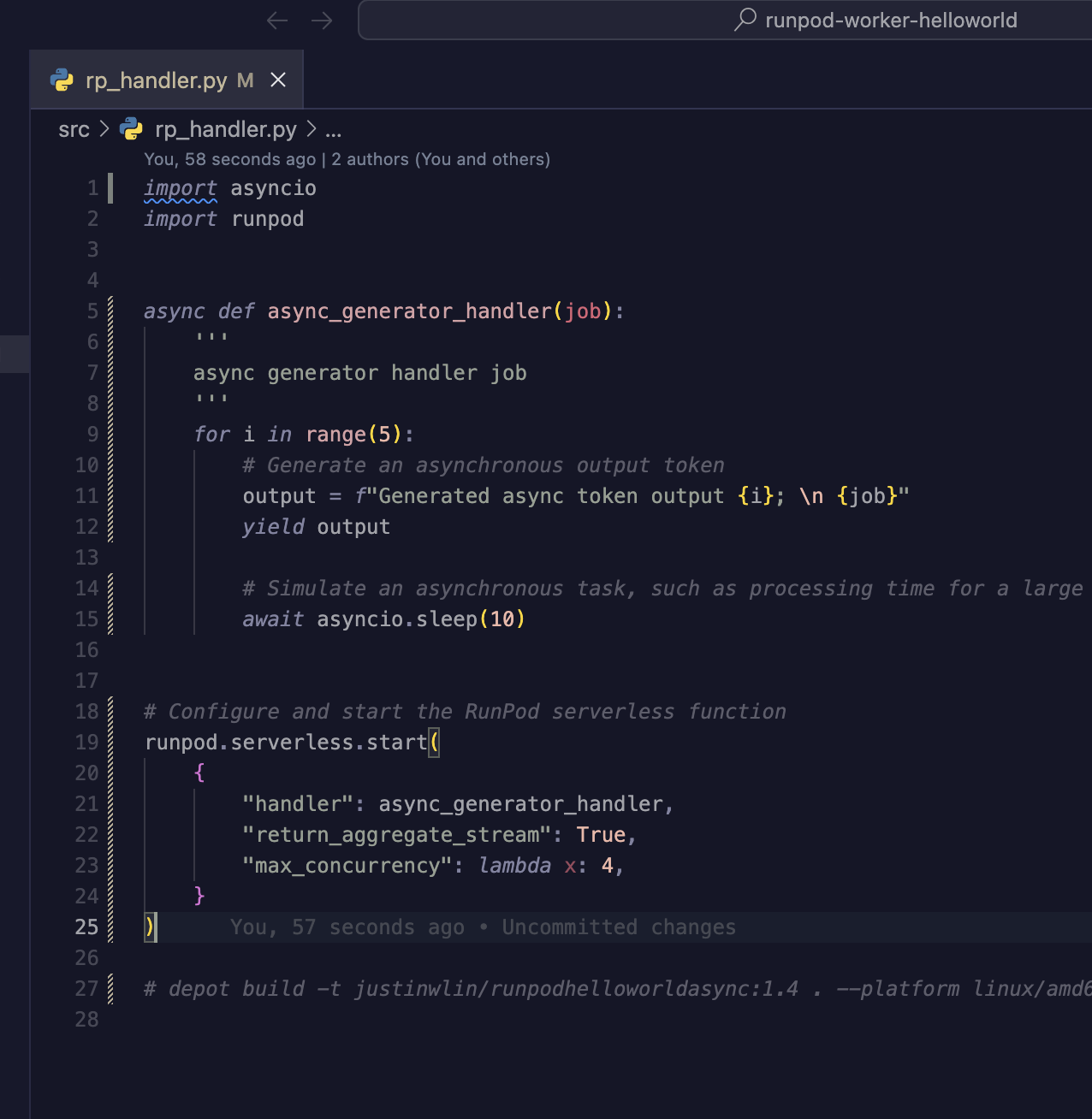
I also tried to add the:
But if I queued up 10 jobs, it would first max out the workers, and just have jobs sitting in queue, rather than each worker picking up to the max number of concurrency modifiers?
https://docs.runpod.io/serverless/workers/handlers/handler-async
RunPod supports the use of asynchronous handlers, enabling efficient handling of tasks that benefit from non-blocking operations. This feature is particularly useful for tasks like processing large datasets, interacting with APIs, or handling I/O-bound operations.