Best PDF Parsing Practices?
I have a system that gets a bunch of legal documents. The documents are all for the same legal case type but they are not the same documents, as each lawyer has their own wording, they look and are formatted diff but have the same important info of course. I want to extract certain data. What is the best approach for this?
As of now I am leaning towards: Anyscale JSON Mode that returns json object of vals I ask for, thoughts? https://www.anyscale.com/blog/anyscale-endpoints-json-mode-and-function-calling-features
^ Credit to Rauch https://github.com/rauchg/next-ai-news
https://github.com/rauchg/next-ai-news
As of now I dont see how I can escape AI for this, but want to ensure I maximize the best model/service for this and not waste money on things I dont need (like throwing chatgpt-4o for example which is much more expensive for a model I dont need)
Any ideas from anyone who did things similarly?
As of now I am leaning towards: Anyscale JSON Mode that returns json object of vals I ask for, thoughts? https://www.anyscale.com/blog/anyscale-endpoints-json-mode-and-function-calling-features
^ Credit to Rauch
https://github.com/rauchg/next-ai-newsAs of now I dont see how I can escape AI for this, but want to ensure I maximize the best model/service for this and not waste money on things I dont need (like throwing chatgpt-4o for example which is much more expensive for a model I dont need)
Any ideas from anyone who did things similarly?
Anyscale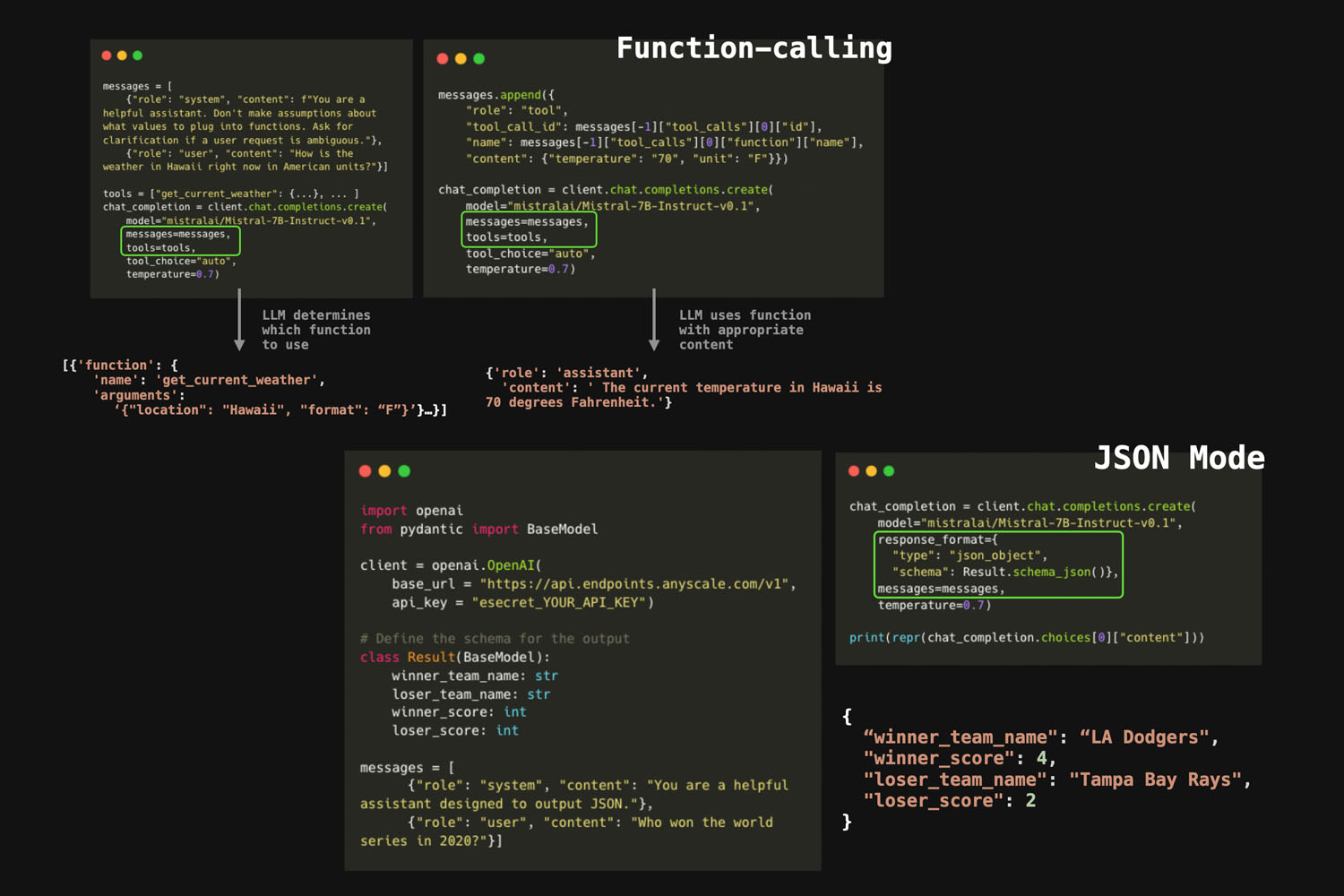
Anyscale is the leading AI application platform. With Anyscale, developers can build, run and scale AI applications instantly.
GitHub
Contribute to rauchg/next-ai-news development by creating an account on GitHub.

Was this page helpful?