op_traversal P98 Spikes
Hi TinkerPop team!
I'm observing these abrupt spikes in my gremlin server P98 metrics in my JanusGraph environment. I've been looking at the TraversalOpProcessor (https://github.com/apache/tinkerpop/blob/master/gremlin-server/src/main/java/org/apache/tinkerpop/gremlin/server/op/traversal/TraversalOpProcessor.java) code over the last couple days for some ideas of what could be causing it but I'm not seeing an obvious smoking gun so figured I'd ask around.
The traversal in question is being submitted from Rust via Bytecode using gremlin-rs. Specifically with some additions I've made that added mergeV & mergeE among other things. It's in a PR awaiting the maintainer's review, but that's not really relevant to my question, but over here if you want to see it: https://github.com/wolf4ood/gremlin-rs/pull/214. The GraphSONV3 serializer is what's being used by the library.
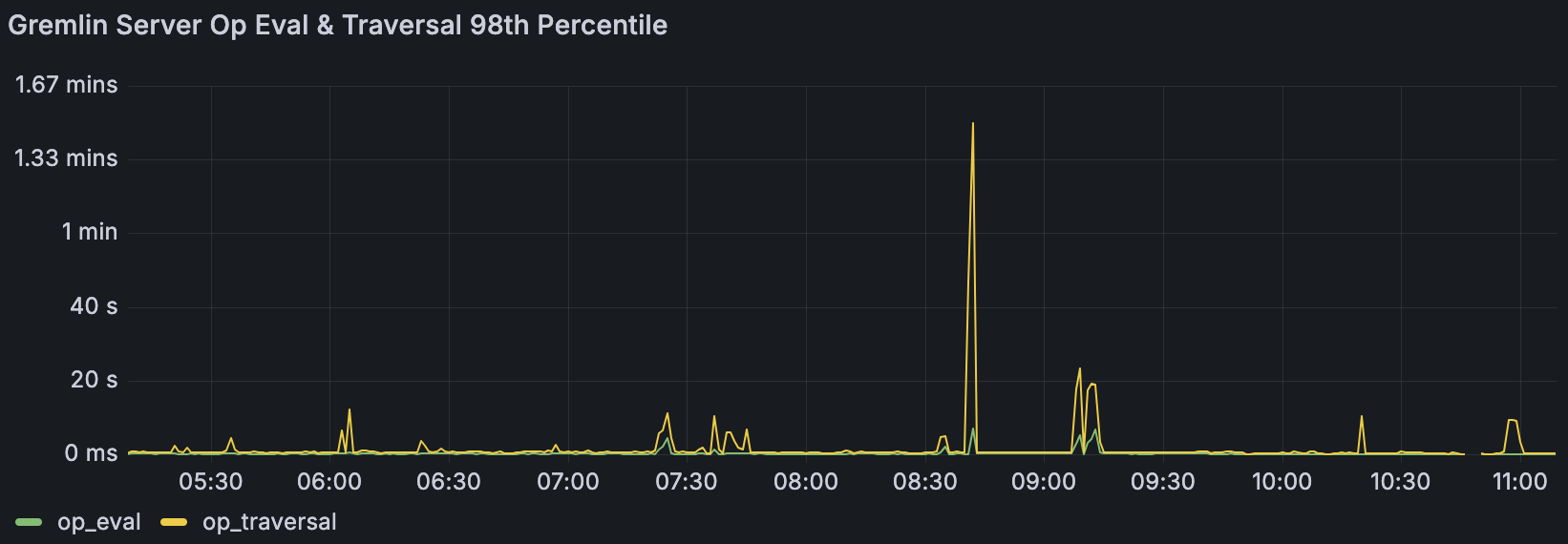
Attached is a screenshot of the spikes I'm referring to. When not having these abrupt spikes to seconds & minutes the baseline P98 is usually around 300-700ms. I have a worker thread pool of 16, gremlin pool of 8, and the default boss pool of 1. The underlying host has 8 cores, but I rarely see its cpu load go above 2. The worker thread pool of 16 was part of an attempt to see if I could get more writes out the otherside of JanusGraph, before I found the metric that showed its CQLStoreManager was not building up a queue after all.
I'm observing these abrupt spikes in my gremlin server P98 metrics in my JanusGraph environment. I've been looking at the TraversalOpProcessor (https://github.com/apache/tinkerpop/blob/master/gremlin-server/src/main/java/org/apache/tinkerpop/gremlin/server/op/traversal/TraversalOpProcessor.java) code over the last couple days for some ideas of what could be causing it but I'm not seeing an obvious smoking gun so figured I'd ask around.
The traversal in question is being submitted from Rust via Bytecode using gremlin-rs. Specifically with some additions I've made that added mergeV & mergeE among other things. It's in a PR awaiting the maintainer's review, but that's not really relevant to my question, but over here if you want to see it: https://github.com/wolf4ood/gremlin-rs/pull/214. The GraphSONV3 serializer is what's being used by the library.
Attached is a screenshot of the spikes I'm referring to. When not having these abrupt spikes to seconds & minutes the baseline P98 is usually around 300-700ms. I have a worker thread pool of 16, gremlin pool of 8, and the default boss pool of 1. The underlying host has 8 cores, but I rarely see its cpu load go above 2. The worker thread pool of 16 was part of an attempt to see if I could get more writes out the otherside of JanusGraph, before I found the metric that showed its CQLStoreManager was not building up a queue after all.
GitHub
Apache TinkerPop - a graph computing framework. Contribute to apache/tinkerpop development by creating an account on GitHub.
GitHub
GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.


Solution
For anyone else that finds this thread the things I ended up finding to be issues:
- Cassandra's disk throughput I/O (EBS gp3 is 125MB/s by default, at least for my use case a I was periodically maxxing that out, increasing to 250MB/s resolved that apparent bottleneck). So if long sustained writing occured the 125MB/s was not sufficent.
- Optimizing traversals to using mergeE/mergeV that were either older groovy-script based evaluations I was submitting or older
The former was identified using EBS volume stats and confirming at a lower level using
- Cassandra's disk throughput I/O (EBS gp3 is 125MB/s by default, at least for my use case a I was periodically maxxing that out, increasing to 250MB/s resolved that apparent bottleneck). So if long sustained writing occured the 125MB/s was not sufficent.
- Optimizing traversals to using mergeE/mergeV that were either older groovy-script based evaluations I was submitting or older
fold().coalesce(unfold(),...)The former was identified using EBS volume stats and confirming at a lower level using
iostats