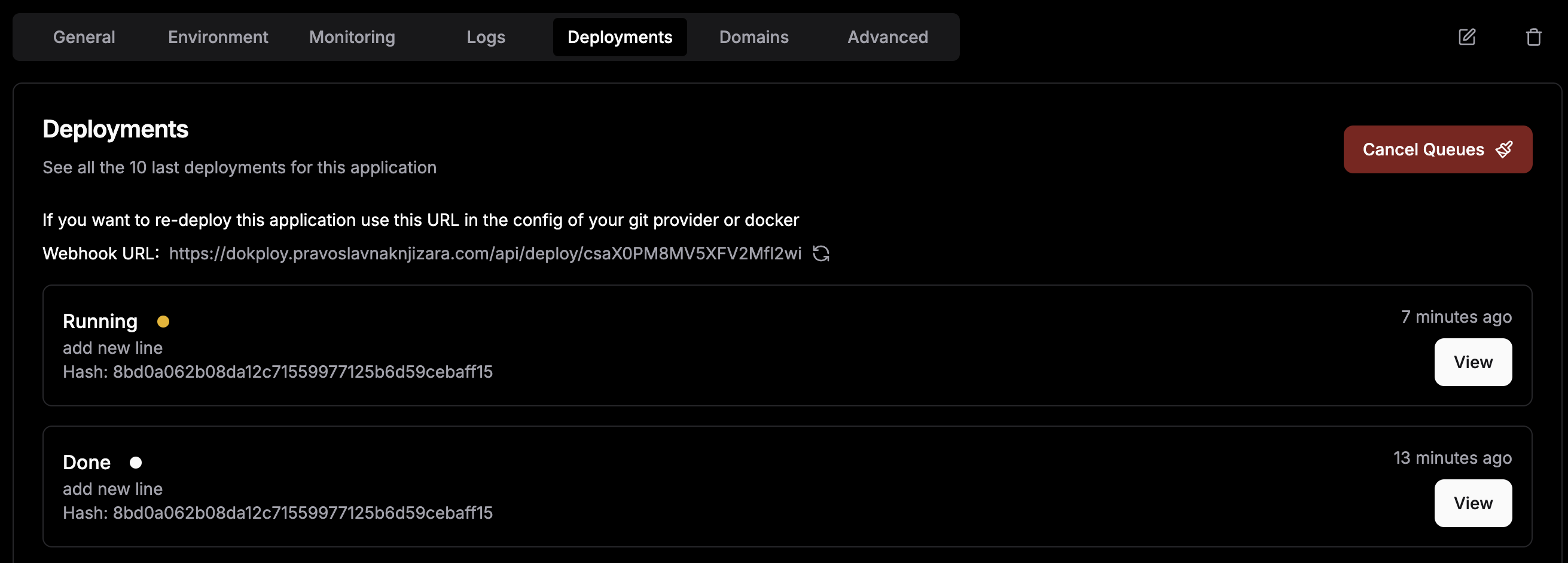
Restarting a server causes deployment to run again
Hello 
I have noticed that turning a Server OFF and ON on Hetzner might cause Dokploy to trigger a deployment when it is starting,
although the "autodeploy" button is off.
I expect that a new deployment is triggered only when:
- i press the deployment button
- when the autodeploy button is enabled and I push a commit
I do not expect a new deployment to be triggered:
- when I restart my server instance
Other info:
It tries to redeploy a commit that has already been deployed. (see image)
I have noticed that turning a Server OFF and ON on Hetzner might cause Dokploy to trigger a deployment when it is starting,
although the "autodeploy" button is off.
I expect that a new deployment is triggered only when:
- i press the deployment button
- when the autodeploy button is enabled and I push a commit
I do not expect a new deployment to be triggered:
- when I restart my server instance
Other info:
It tries to redeploy a commit that has already been deployed. (see image)