vLLM serverless output cutoff
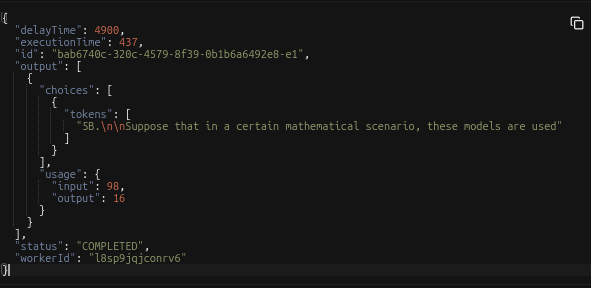
I deployed a serverless vLLM using deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
But when i made a request, output is only 16 tokens (tested many times), I don't change anything from default setting but max_model_length to 32768.
How can i fix that? or did I miss any config?
But when i made a request, output is only 16 tokens (tested many times), I don't change anything from default setting but max_model_length to 32768.
How can i fix that? or did I miss any config?