Hardware Performance Guidance and Bottleneck Debugging
Background
I'm currently running CS in docker containers on a Raspberry Pi 5. Rough overview:
* CS primary container - CAPI, LAPI, used by nginx bouncer (remote on another machine)
* CS secondary container - Child log processor acquiring from nginx docker source (remote on another machine)
* 9 collections installed
* 10 parsers (http-logs, nginx-logs, some enrich, non-syslogs, whitelists...)
CS works fine for my setup. 99% of the time it's using less than 1% cpu. My server averages 0-30 req/s ingress.
But every once in awhile I do something that gets a ton of ingress (mastodon post) and have 1000+ req/s at which point CS takes my Pi5 to 100% cpu usage. It looks to be about 50/50 split between secondary container and primary (for bouncing, I'd guess).
Problem
I've looked through the docs and done some thorough googling.
* CS Docs recommend ARM, 1 cpu core, 100 ram minimum but this is clearly not sufficient for large loads.
* Config docs specify some
routines settings but other than this one blog post its not clear what the recommended values for these should be based on hardware or load
There is very little documentation on how to scale hardware based on expected load. There is, as far as I can tell, no documentation on how to troubleshoot bottlenecks or otherwise get insight into what would need to be tweaked in order to get better performance.
Can the CS team provide a bit of insight on these topics?21 Replies
Important Information
Thank you for getting in touch with your support request. To expedite a swift resolution, could you kindly provide the following information? Rest assured, we will respond promptly, and we greatly appreciate your patience. While you wait, please check the links below to see if this issue has been previously addressed. If you have managed to resolve it, please use run the command
/resolve or press the green resolve button below.Log Files
If you possess any log files that you believe could be beneficial, please include them at this time. By default, CrowdSec logs to /var/log/, where you will discover a corresponding log file for each component.
Guide Followed (CrowdSec Official)
If you have diligently followed one of our guides and hit a roadblock, please share the guide with us. This will help us assess if any adjustments are necessary to assist you further.
Screenshots
Please forward any screenshots depicting errors you encounter. Your visuals will provide us with a clear view of the issues you are facing.
© Created By WhyAydan for CrowdSec ❤️
There's a few things you can try to reduce CPU usage:
- Use the firewall bouncer over the NGINX bouncer, it'll be a fair bit lighter since the bad IPs will be blocked at the network level, reducing the amount of logs CrowdSec has to parse, and for NGINX having to process those requests.
- Remove any collections, parsers, and scenarios you don't need, the geoip parser in particular is quite heavy
- Enable RE2 feature flag for a big reduction in CPU at the cost of more RAM usage https://docs.crowdsec.net/docs/next/configuration/feature_flags#list-of-available-feature-flags
Feature Flags | CrowdSec
In order to make it easier for users to test and experiment with new features, CrowdSec uses the concept of "feature flags".
Thanks for the feedback. I'll remove geoip, I had a hunch that was costly and I'm only using it for nice looking notifications to discord.
Firewall bouncer isn't an option, unfortunately, because 1) the burst of requests are all valid (normal operation of mastodon when posting to a highly-followed user) and 2) I'm using cloudflare tunnels and CS recommends not using the firewall bouncer on the free tier
Enable RE2 feature flagFrom the docs and cscli output I was under the impression this was deprecated and will be removed?
Firewall bouncer isn't an option, unfortunately, because 1) the burst of requests are all valid (normal operation of mastodon when posting to a highly-followed user) and 2) I'm using cloudflare tunnels and CS recommends not using the firewall bouncer on the free tierYou can try the Cloudflare bouncer instead, but it'll be heavily rate limited. Not sure how much help that'll be.
From the docs and cscli output I was under the impression this was deprecated and will be removed?I think it's going to be enabled by default at some point, but I'm personally using that flag and it had a nice impact on performance
Thanks for the clarification. Do you have any guidance on tuning
routines settings?
Also I realize (I think) you are a power user and not a dev so getting info on hardware scaling may be out of scope. Is there somewhere better I can post this question to get dev attention?that's for the AppSec WAF, are you using that?
Also I realize (I think) you are a power user and not a dev so getting info on hardware scaling may be out of scope. Is there somewhere better I can post this question to get dev attention?A dev should get to you if your still having issues but I've been using CrowdSec for years so I'm fairly experienced
I am not using appsec yet. I didn't realize those settings were specific to that feature.
What has been your personal experience with hardware requirements for the peak loads I have experienced?
fyi, AppSec is pretty heavy so you might want to offload the WAF functionality to Cloudflare.
CrowdSec is pretty heavy since it makes heavy use of regex, so I wouldn't expect a raspberry pi to handle it well except for a low traffic home server. 1000+ requests a second would probably be a bit too much
if you can offload some of those requests to Cloudflare via caching, that'll be a big help.
Gotcha. I'll enable re2 and remove geo-ip but it sounds like I should migrate it to a beefier server I have in my lab.
@FoxxMD https://github.com/crowdsecurity/crowdsec-docs/issues/735 fyi should be better documented in the future
GitHub
Add a dedicated section on performance tuning · Issue #735 · crowds...
Performance advice is currently scattered all around the docs, some not at all making it difficult to better tune your CrowdSec installation for performance.
hey 👋 the biggest cpu cost is this one scenario https://app.crowdsec.net/hub/author/crowdsecurity/scenarios/http-bad-user-agent so you shouldnt have to remove the geoip module as that should be pretty light @FoxxMD but yeah it sounds good to do, just dont know exactly where it would end up.
CrowdSec Console
Hub configuration
Use CrowdSec Console to visualize security data, manage dynamic blocklists, and gain real-time intelligence on IPs. Enhance your threat response capabilities.
Thanks for the feedback @iiamloz . That is present in my config, I'll figure out what collection is including it and remove it. Glad to know I can keep geoip as that is nice info to get pinged with
For your one container you can add
DISABLE_SCENARIOS environment and for bare metal just run cscli scenarios remove 😄oh that's dope! I see that now in
docker_start.sh I've been having to dig into the source code to find all these extra, useful ENVs. Wish they were in docs 🥲GitHub
crowdsec/docker/docker_start.sh at master · crowdsecurity/crowdsec
CrowdSec - the open-source and participative security solution offering crowdsourced protection against malicious IPs and access to the most advanced real-world CTI. - crowdsecurity/crowdsec
they should be on docker readme, but its not the best place to find them https://hub.docker.com/r/crowdsecurity/crowdsec
ah i see that now, thanks for the tip
I moved CS to a more powerful machine (10 cores on an i5-13400), enabled re2, and disbaled user agent matching. ofc the better machine helped and my issues are functionally resolved.
i did reply to daniel stenberg (curl owner) which netted ~4000 requests over about 10 seconds and it still saturated all 10 cores but at least my systems and web server didn't freeze this time 😵💫
marking this as solved.
another idea just came to mind, are you running a reverse proxy, are you parsing the logs on both your reverse proxy and webserver, or just the reverse proxy?
Running a reverse proxy. I've offloaded the log parsing to a separate log processor. The reverse proxy uses bouncer from a primary CS instance not processing any logs. Generally:
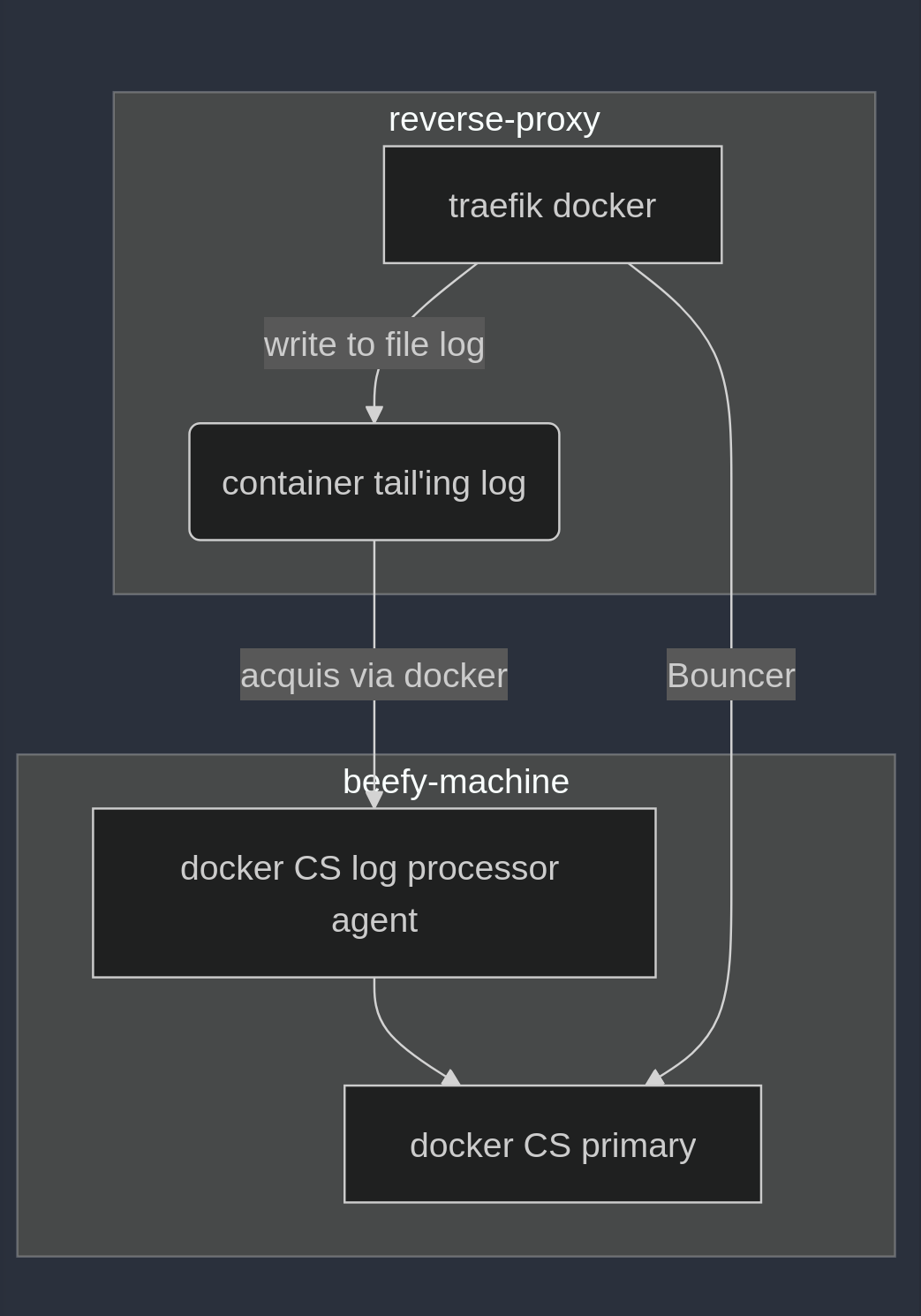
but are you parsing both the web server logs (backend) and reverse proxy, or just your reverse proxy?
I'm not sure what the difference is, in this case. this traefek instance only serves external requests, from cloudflare tunnel. requests are written to access.log
oh actually this is nginx 😂 but the setup is entirely the same. im in the middle of migrating to traefik but external is still all through nginx
oh i think i understand what you mean
.
reverse proxy -> routes to -> service a
-> logs -> logs
Cs is only processing logs from the reverse proxy
aah good, because if you were parsing both on the web server and reverse proxy you'd be parsing the same logs twice