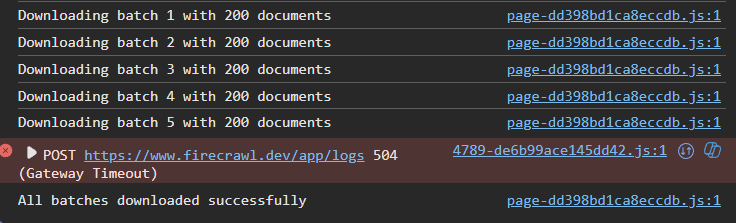
downloading large crawl from dashboard fails
How can you download a large crawl job's output (5k documents)? Doing it through the dashboard fails as it sometimes downloads the first part of it (in JSON or md formats) and others nothing, so how can we use the returns from these large jobs?