Where is the 250ms cold start metric that you advertised derived from?
I am using the faster-whisper template with flashboot and I get ~20s of delay time + 500ms/1s of execution time. How can I acheive a 250ms cold start time?
74 Replies
I'm not familiar with our advertising, so no idea where that comes from but I am super familiar with Faster Whisper and I know that by default we download every single model for you which sucks. 1s execution time tracks but the biggest thing is that model download on startup.
@Dj here's the advertising mentioned, on the home page on login. Either way, I assume it's not possible due to the time it takes to download whisper-large-v3-turbo to the server on cold start? Is there any way to reduce the time?
I succeeded by forking the template and baking turbo into the model. https://github.com/partyhatgg/runpod-faster-whisper
GitHub
GitHub - partyhatgg/runpod-faster-whisper
Contribute to partyhatgg/runpod-faster-whisper development by creating an account on GitHub.
I care a lot about super optimizing Faster Whisper on RunPod, this is my project from before I joined the company and I truly don't think it gets any better than where it is now. Just using the latest version of Faster Whisper baking the model I need, etc
so this is with the model downloaded onto the docker image?
Yes, this one loads medium and turbo though for my own purposes
You can experiment with it by trying
ghcr.io/partyhatgg/runpod-faster-whisper:main but you will need a GitHub Container Registry Authseems like the worker still has to download the docker image which takes significant time. Is there a way to cache it?
would it be better to just use the default whisper template with the models downloaded in network storage that container mounts? Or is that effectively the same?
Unknown User•5mo ago
Message Not Public
Sign In & Join Server To View
@Jason how long will the service go from idle to no workers?
or will there always be an idle worker unless manually removed?
Unknown User•5mo ago
Message Not Public
Sign In & Join Server To View
Have you got it work for the cold start as they are advertising ? I don’t want to sign up and then see that each cold starts takes several seconds
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
Are you sure ? As the OP said it’s not so fast
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
So I gonna send a request for getting back a search intent, then around 200-300ms for the cold start plus execution 100-200ms, shutting down and I’m paying them only the 3 seconds minimum, right ?
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
Great. I gonna set up and forget as it gonna be used for classification of the search intent. And maybe for clustering
I’ve set it up. Do you know how to download the model before running a request ? I’m using the serverless and have an endpoint. But when running the endpoint its timeout after 60 seconds. I think it’s cause the model isn’t downloaded yet
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
Just doing right now 😅 but how to upload it to runpod ? 🤷🏻♂️
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
What do you mean by registry ? Isn’t there again a latency to pull the docker image or will it be done only one time when creating the endpoint ?
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
Ok. So i just upload to s3 and paste the url to runpod serverless inside the env ?
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
Ok. So I just download the model and put it into the docker image file? Or do I need to add any additional script to it ?
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
Yes
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
Ty. I’ve uploaded it to my docker hub and entered the path into endpoint -> docker config.
Now I saved it and it’s showing „initializing“ -> this is normal cause it pulls the 13gb image, right ?
Its working now but still has a 20s delay time (instead of the advertised 250ms for a cold start) even when the model is inside the docker file. 2 times it was around 1000ms but when waiting too long it gets up to 20s again
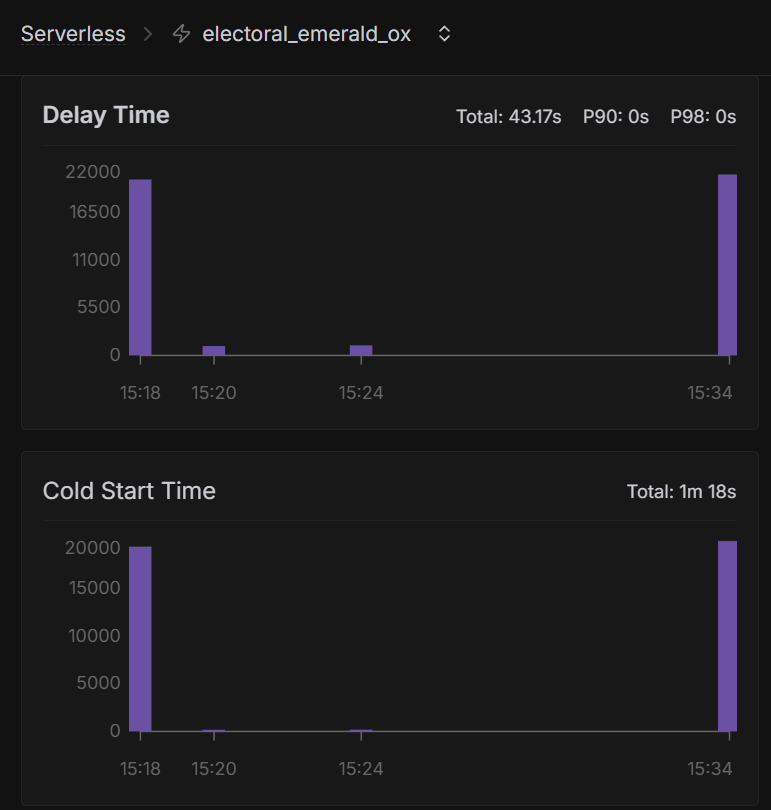
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
The start up time isn’t charged?
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
If it would be normal then it would be warm start and not a cold start. That was my entire question before starting setting runpod up and spending hours doing the correct set up 😒

Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
But this is still not a cold start. For this i don’t need to use runpod and manage another software in my workflow. Then
I could better stick to Google gpu 😅
Im taking about idle workers. When rerunning the request again start up time 20 seconds
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
Cause something is running behind the scenes that it keeps the instance „warm“ for a specific time. So when sending each 5 mins a request everytime I pay 20s for the startup instead of the advertised 250ms. Even if it’s 1s it’s quit okay for me. But 20s x 100 times a day would roughly be around 30mins only for startup
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
Yes. T4 is at 0.35/hour
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
Yes but just a small amount of minutes. It’s not warm the whole time.
Same cold start timing. Advertising <250ms but it will be the same as before except running 24/7 which isn’t useful. For 24/7 I could run a desktop pc with an rtx2060 at my office which doesn’t cost as much as a 24/7 cloud gpu
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
One minute. Heading back to computer. You mean the app.py? It’s not the one from GitHub
Flashboot activated but it’s not keeping it warm the whole time
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
Im using qwen embedding 4b as I need to run clustering tasks
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
Yes the model is inside the docker image
I think they are more than enough
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
Not useful for my usecase as such power isnt needed. Its the case of advertising a cold start under 250ms while its taking 20s. Nothing to do with the used gpu which is attached. It wont make it down to 250ms
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
I dont think its big at around 8gb for the model itself on a 40gb gpu
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
which gpu are you selecting?
oh i see A5000s, your not able to get ms coldstart at all, even back to back requests after a minute?
these are cold-start times for past 24 hours, you can see more than 50% coldstart get < 200ms, in order to achieve this you need to have some type of volume and back and forth requests, you should be able to achieve it in your tests by waiting a minute or so and sending request

the best chance of flashboot is highly correlated to higher available of gpus, e.g. 4090s is the best one due to higher supply
Also saw it. Advertising really bad. Money spent useless 😅
They should advertise it to have whole time continuous request to the endpoint to get the fast cold start instead of misleading a new user that cold starts are available at around 250ms.
If I would have knew this before I wouldn’t even think about using runpod as they are cheaper options available on the market with such cold start timings 😁
it doesn't have to be continuous but continuous does increase the chances of a faster cold start, it's all about balancing supply and demand and i understand the frustration, so far we don't have an offering where you can pay to get piority for flashboot
if you have low volume your benefit will be smaller compared to someone with a higher volume, sadly demand scale skews in their favor
If Im sending continuous request to a gpu then I wouldn’t need cold starts as then there are also cheaper options to run a 24/7 gpu
Low volume doesn’t have a benefit cause 20s of startup time (even a small 0.6gb model included inside the container image) needs 20s which is paid while the tasks run 2-4s
My desktop gpu runs it within 1-2s while it’s „only“ a rtx2060. So I could better let a desktop run with an attached rtx2060 and I will benefit more from it at around 20-30usd per month for electric costs
you don't need 24/7, thats the point im making, it just can't be an hour later, e.g. if few gaps of minutes can get you <1s cold start then you can save the cost of about 60-80% of the gpu cold-start and also lower gpu cost due to scale down
20s for a tiny model means something is off, there is likely chance its downloading the model again or doing some caching
After 3-5mins it’s already taking another 20s to start. Sometimes it works, mostly not. So when requesting 100 calls per day I’m paying for the startup time everytime
majority of coldstarts fall under 10s, so yours being this high for a tiny model is not normal
Nope. Tested it with several images. No downloading happening
have you tried with 4090 and see if its same coldstart?
I’ve chosen different ones while had 4 on the dame endpoint to get everytime a response even with low supply. But I don’t think that it will make a big difference as the loading process of the image is taking the most time
Is it correct that I implement the whole system into the docker image with all the necessary things which need to be inside when running it ? Or only the model itself ? Maybe this the issue?
< 1gb model taking 20s is not normal in any means, that is way too slow
yes include all things, you don't want any internet traffic when initializing, no reason to do that unless you have files that change
pm me endpoint id, ill take a look at logs
Ok then I have done it right to prevent any downloads
Ok Ty
Unknown User•2mo ago
Message Not Public
Sign In & Join Server To View
we were able to see < 200ms cold starts between at least a minute of requests, goal is to use high availability cards
its obv not perfect, expecting the very low cold starts between hours of idle time is unlikely to occur
If you hit the endpoint within 1-3 minutes again then the cold start is around 250-1000ms. So quite fast. If you hit it later the chance to get a fast cold start is lower as much time passed since last hit. That’s the issue