Why is this taking so long and why didn't RunPod time out the request?
Serverless endpoint: vLLM
Model: meta-llama/Llama-3.1-8B-Instruct
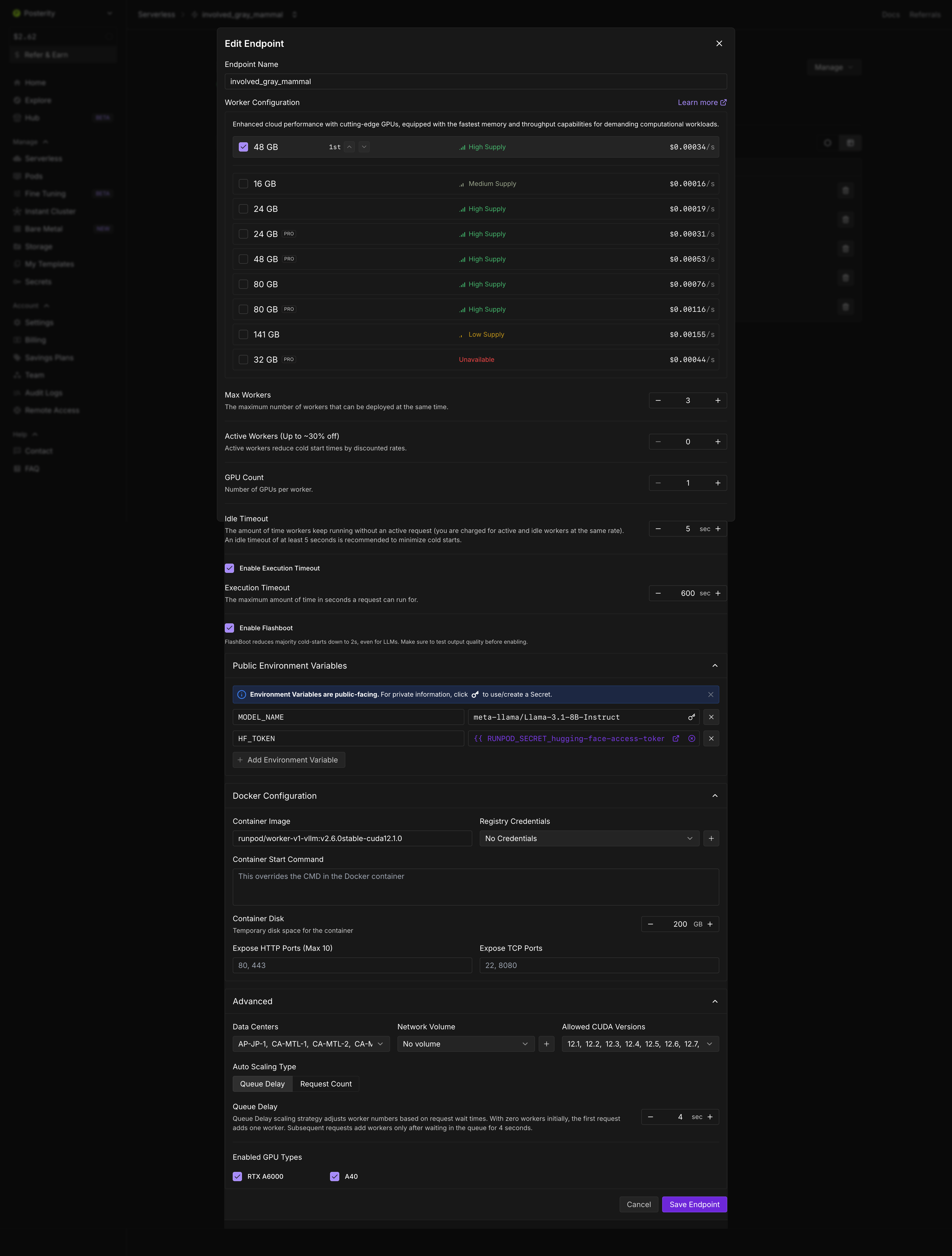
GPU: 48GB A40
I have a prompt to extract facts from a meeting transcript. When I run the prompt on
When I run the same prompt on my RunPod serverless endpoint with the above specs, it has been running for over an hour. Logs, telemetry & config attached.
Questions:
1. Why is this taking so long?
2. The execution timeout is 600 seconds (10 mins) - why didn't RunPod time out the request?
3. I sent a couple more requests - why are they stuck behind the first on the same worker instead of being served by the remaining 2 inactive workers as per the queue delay setting?
Really appreciate help here been in a muddle with this for a while
been in a muddle with this for a while
Model: meta-llama/Llama-3.1-8B-Instruct
GPU: 48GB A40
I have a prompt to extract facts from a meeting transcript. When I run the prompt on
o4-mini-2025-04-16When I run the same prompt on my RunPod serverless endpoint with the above specs, it has been running for over an hour. Logs, telemetry & config attached.
Questions:
1. Why is this taking so long?
2. The execution timeout is 600 seconds (10 mins) - why didn't RunPod time out the request?
3. I sent a couple more requests - why are they stuck behind the first on the same worker instead of being served by the remaining 2 inactive workers as per the queue delay setting?
Really appreciate help here
been in a muddle with this for a while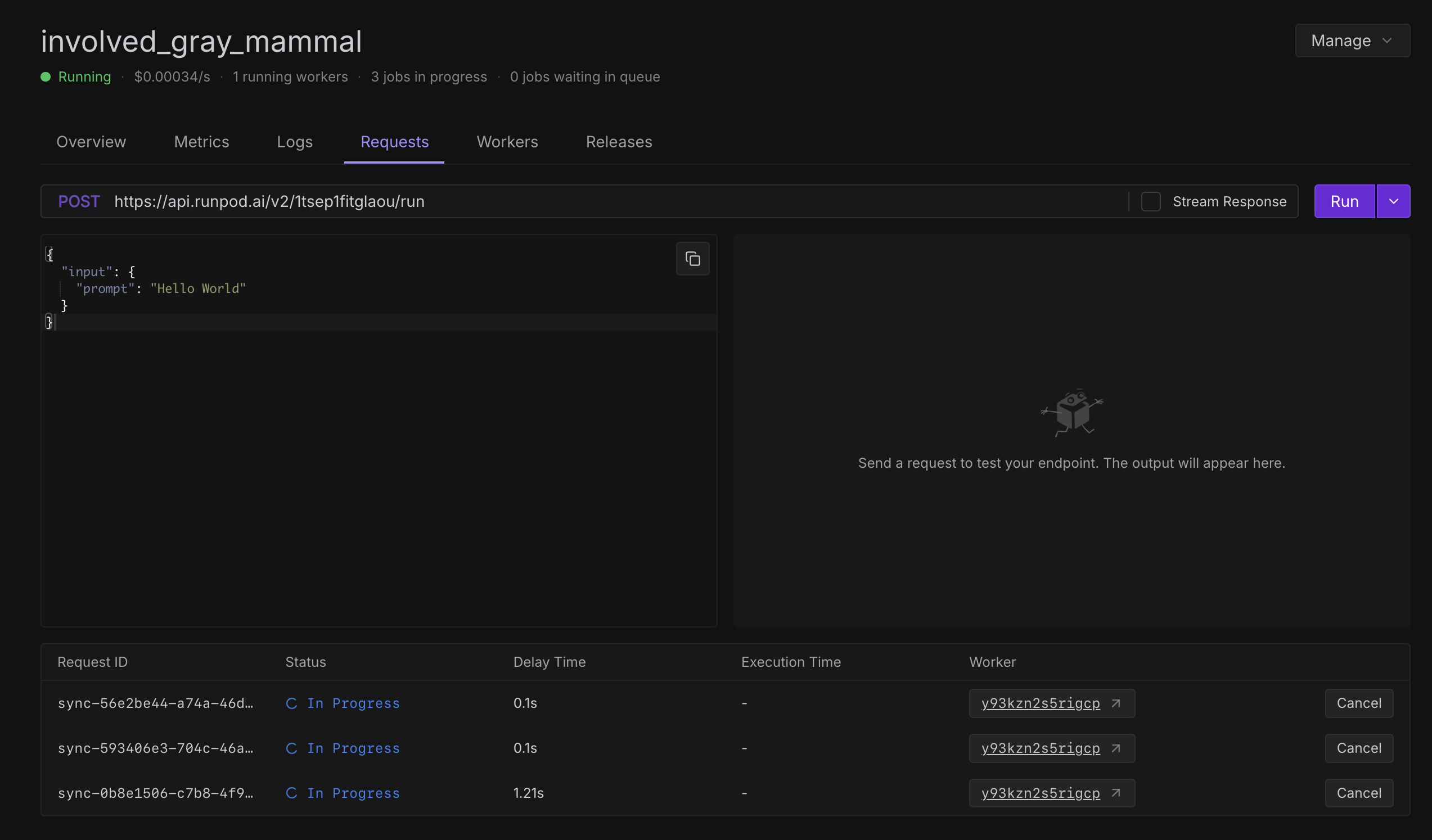
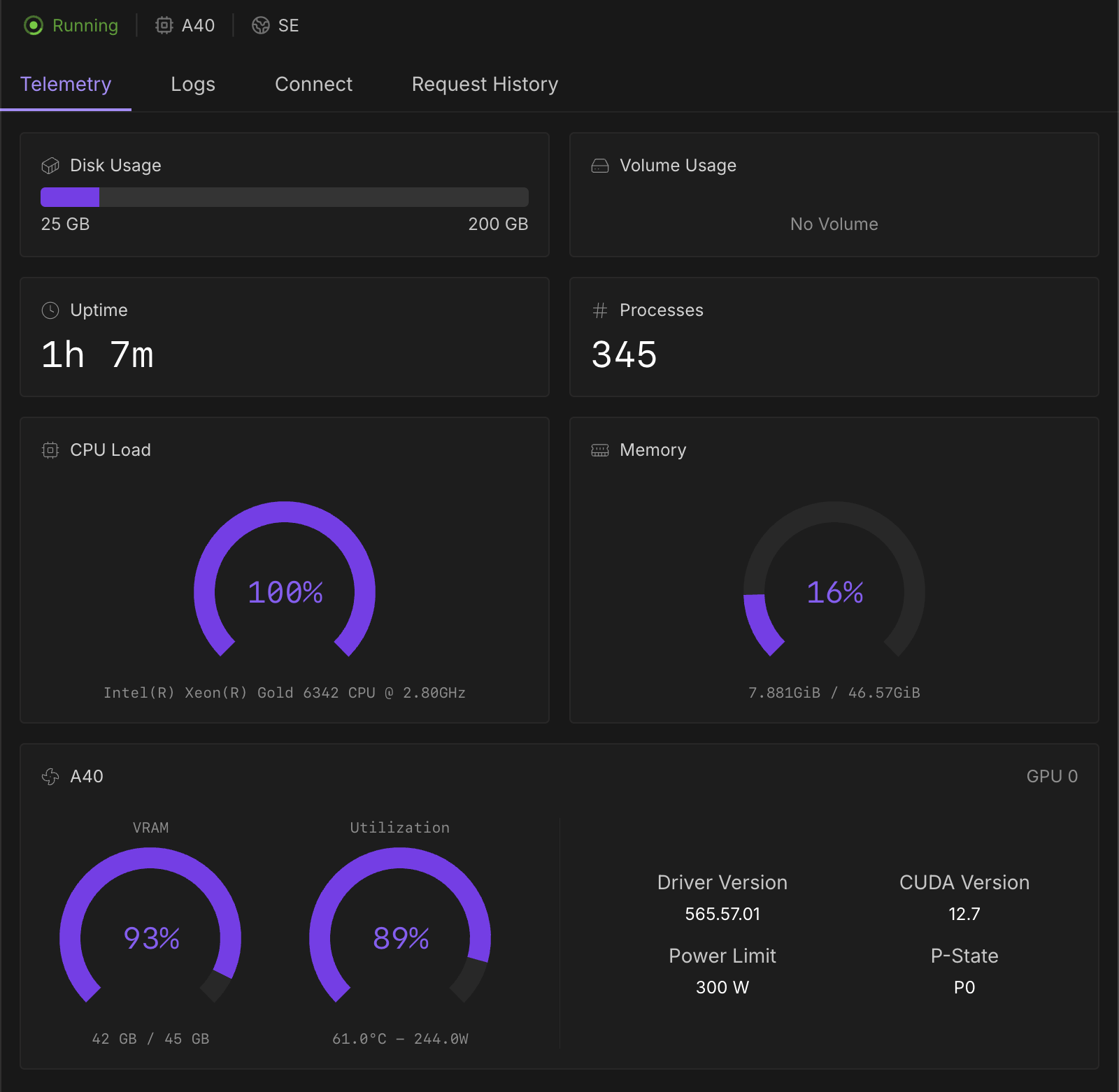
logs.txt188.02KB