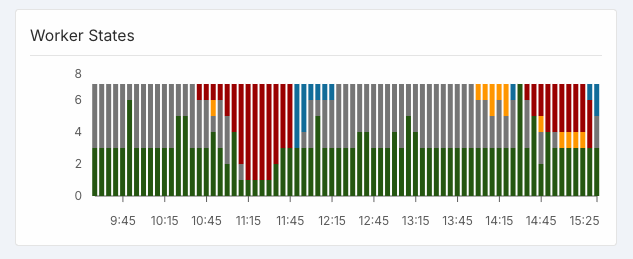
Unhealthy workers keep sabotaging production
As you can see, somehow 2/3 active workers + all flexible workers became unhealthy. I don't know the reason for this or if I have any power to fix it. However, without my involvement Runpod doesn't kill those workers and doesn't replace them automatically with healthy workers making my prod unstable. To resolve this incident I needed to manually kill unhealthy workers. I need some support on how to prevent or handle this situation.