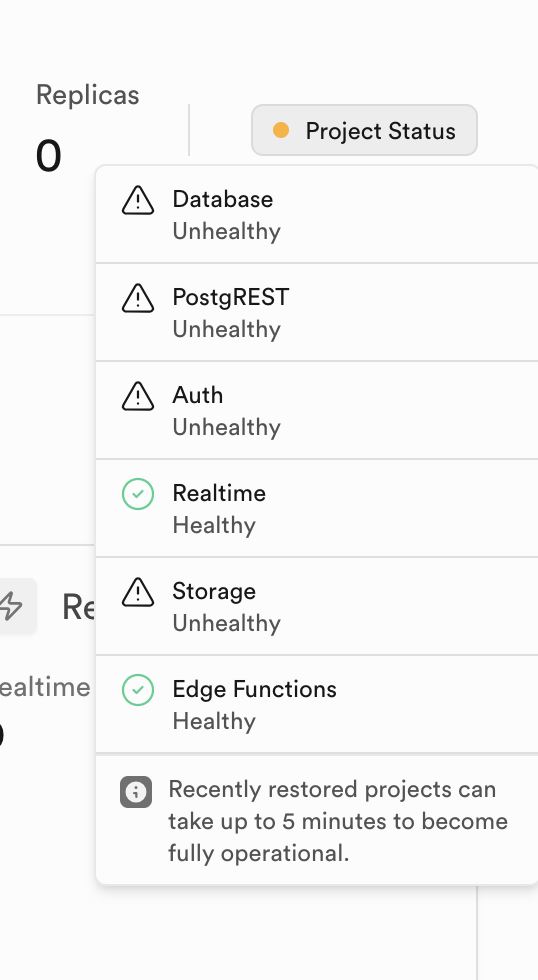
Supabase Intermittently Stops Working.
My project has been healthy and been active for months. Starting 2 days ago it's been intermittently becoming unresponsive and my frontend app API calls timeout. My project status shows that it's unhealthy. I've seen everything from Max CPU and Disk/I/O to timeouts. I've been optimizing queries and indexes to help. I've even vaccuumed some tables just in case. Opened two tickets with supabase support, but yet to hear back. My front-end traffic has been steady, but now my customers are getting pissed. Anyone experienced this and maybe solved it?