vLLM - How to avoid downloading weights every time?
I have a Serverless Endpoint with vLLM.
Using this Docker Image : runpod/worker-v1-vllm:v2.7.0stable-cuda12.1.0
My ENV var:
In the worker logs i have :
22 Replies
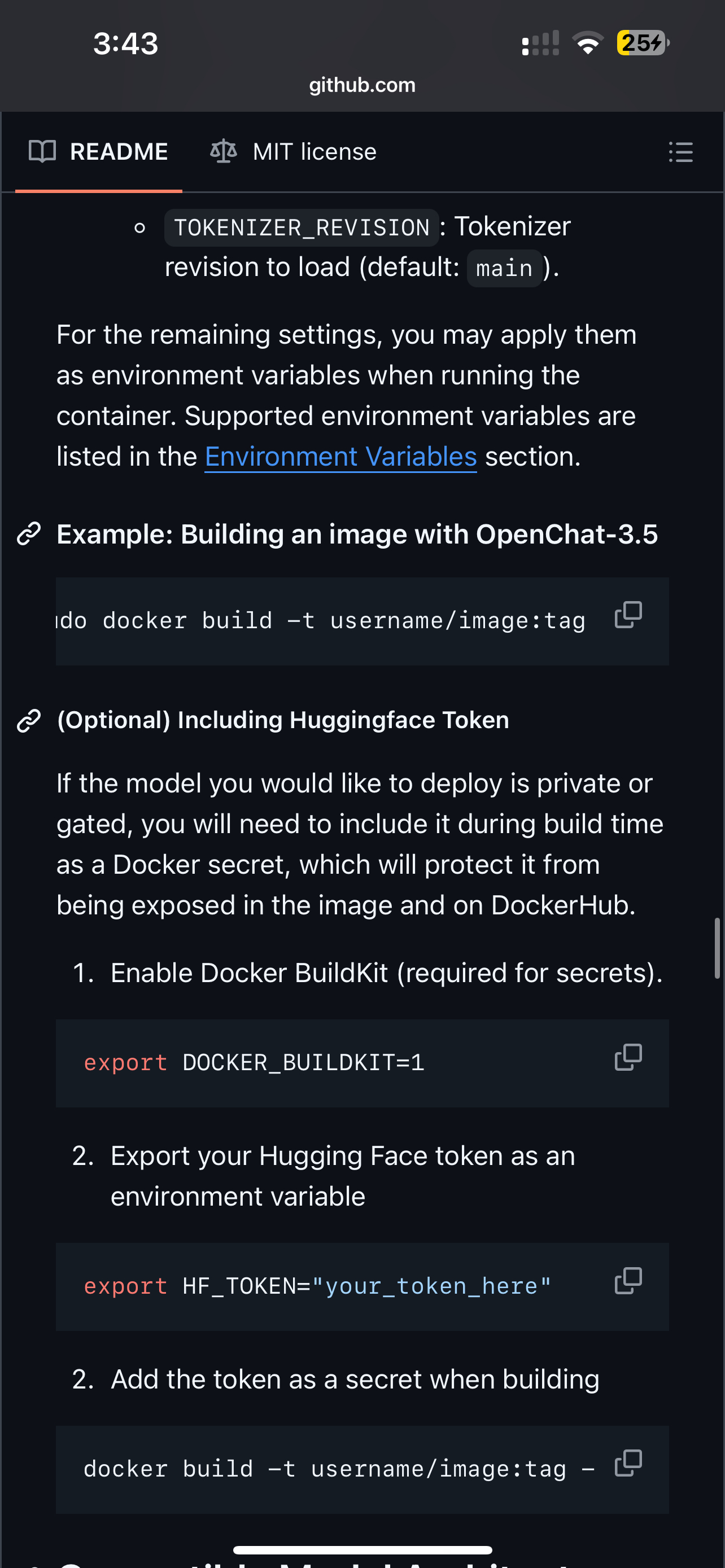
got to bake it into the image. the github repo got some instructions / you can point chatgpt to it to ask for further instructions. Unfortunately that is a problem in general with such things.
https://github.com/runpod-workers/worker-vllm?tab=readme-ov-file#option-2-build-docker-image-with-model-inside
just the model name is probably all you need
GitHub
GitHub - runpod-workers/worker-vllm: The RunPod worker template for...
The RunPod worker template for serving our large language model endpoints. Powered by vLLM. - runpod-workers/worker-vllm
You mean i have to use "Option 2: Build Docker Image with Model Inside"?
No way I can use "Option 1: Deploy Any Model Using Pre-Built Docker Image"?
not to my knowledge. i have the same issue so ive been meaning to make a library of popular models for myself but yeah 😔. the first option is using a base docker image, where it sets the env variables
but that means everytime serverless launches a the base docker image -> its in a default state -> looks at the env variables -> downloads -> run
so if u wanna skip the download step it has to already be in the image
Ok thanks...It's too bad.
So it's much more complicated I think.
So, I don't really understand ...
I understand that I have to make my own Docker image?
But should I first download the weights and put them in my Docker image?
If I do this, what is the point of having a storage?
If I want to put the weights in the storage how do I do it?
It is not possible to start for the first time and download the weights and that then it is no longer necessary?
what u trying to do? what the end goal
I want a vLLM Serverless Endpoint with a quick coldstart
nah basically u just give the dockerfile when u run the build command the argument
as the docker builds the image to docker cloud it will have everything
so whenever u build a dockerfile:
it basically creates a snapshot going through all ur instructions
and then saves that snapshot in dockercloud
so if ur like:
docker build mymodel using this dockerfile instruction
then will download and build itself
u dont need to download and put it in urself manually
(tho i guess thatis what is happening as it builds)
Hmmmmmmm for the first time, im not sure if vllm supports network storage
im actually 🆕 so i havent touched this much
i was thinking about network storage too, but i dont see it described in the readme
having storage is for stuff that utilizes it. not all repositories utilize network storages. but yeah does provide persistence. but network storage can also be slow for i/o operations still
Ok, but as we can set environment variables, I thought it was possible.
I'm going to look to do my own Dockerfile, but frankly I'm not sure I get there.
I know how to build an image and put it on DockerHub. And then deploy it on Runpod.
But I am not sure I can do the Dockerfile on its own from zero. The goal is to use VLLM so that it is simple.
the dockerfile is already there
so u can just run the existing dockerfile command with the arguments
can ask chatgpt but u shouldnt have to make it
should just be download repo
cd to it
maybe install docker if u havent already
and do
GitHub
worker-vllm/Dockerfile at main · runpod-workers/worker-vllm
The RunPod worker template for serving our large language model endpoints. Powered by vLLM. - runpod-workers/worker-vllm
docker build (ur model) the dockerfile already there and push
yeah
has examples
i just throw the url into chatgpt
and tell it what command do i use xD to build and push
for these things
lol
and i give it my hf model url
whenever i do these
(i dont use vllm) but i use other stuff i made
🥱 if i pass out it 4 am for me just fyi. if i disconnect
but hopefully this helps
ok i start to understand.
I will still have to do a lot of research.
Because I do not understand how to download the weights locally so that they are then in my Docker image.
thanks for you help
u dont download locally
u just give it arguments
and as the dockefile builds
will doenload
such as if i made a file such as
arg variable give me a prompt
echo variable
u dont need to download the “prompt”
u just need to do
Yes but at each cold start, there will be a download?
build image (variable)
ah no. bc once the build command is done
ok
it will actually build a snapshot and push it to docker
i get it
and then u use that snapshot
so instead of using runpod image
u use
myname/vllm:1.0
wherever u push to
creating ur own snapshot basically
i would test with a small model first
to make sure things work
and not waste too much time building
It's still weird, because with the configuration I gave above, I see that the weights are still downloaded to my storage.
It's just that on the next startup, it is not able to reuse the weights already downloaded.