© 2026 Hedgehog Software, LLC
Twitter
GitHub
Discord
System
Light
Dark
More
Communities
Docs
About
Terms
Privacy
Search
Star
Feedback
Setup for Free
Status Down? - Supabase
S
Supabase
•
8mo ago
•
46 replies
zold
Status Down?
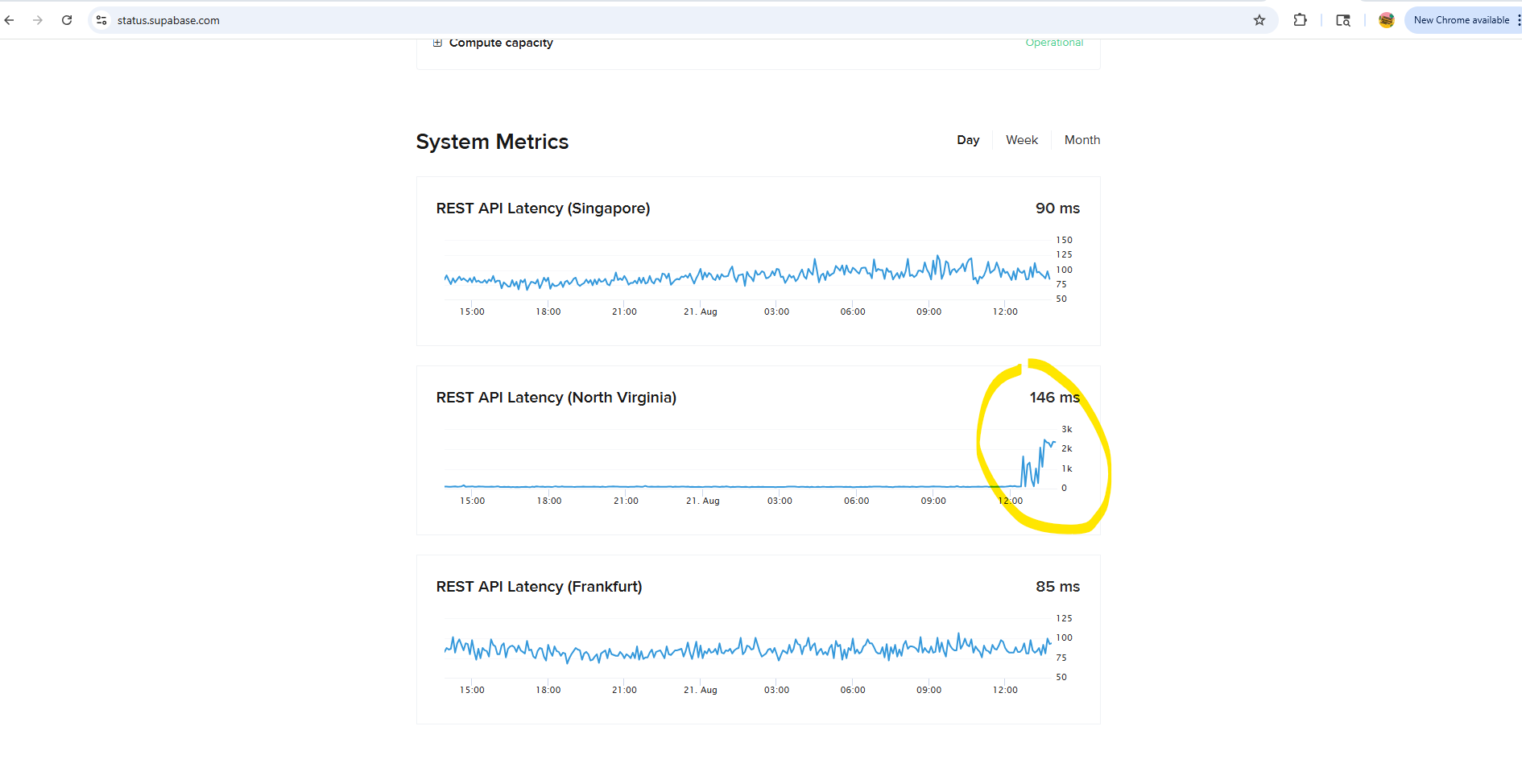
Is supabase having issues for anyone else
?
Supabase
Join
Supabase gives you the tools, documentation, and community that makes managing databases, authentication, and backend infrastructure a lot less overwhelming.
46,176
Members
View on Discord
Resources
ModelContextProtocol
ModelContextProtocol
MCP Server
Similar Threads
Was this page helpful?
Yes
No
Recent Announcements
Similar Threads
Production DB Down After Rollback - Pro Plan - Need Status Update
S
Supabase / help-and-questions
5mo ago
Database Status
S
Supabase / help-and-questions
4w ago
Dashboard down
S
Supabase / help-and-questions
3w ago
Supabase down?
S
Supabase / help-and-questions
4w ago