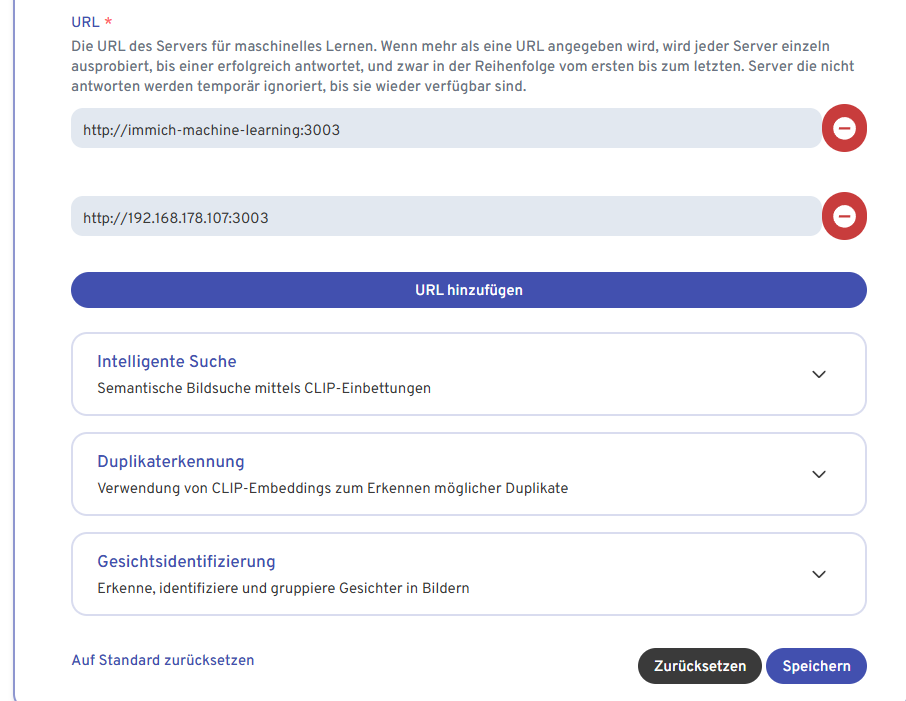
Remote Mashine Learning Settings
hey there
Is remote machine learning also used for duplicate detection?
For which features is remote machine learning used?
In which order are the URLs tested from the web interface — from top to bottom or from bottom to top?
2. I use ans Nvidia RTX 5060 TI and on my WSL this Compose file:
cat docker-compose.yml
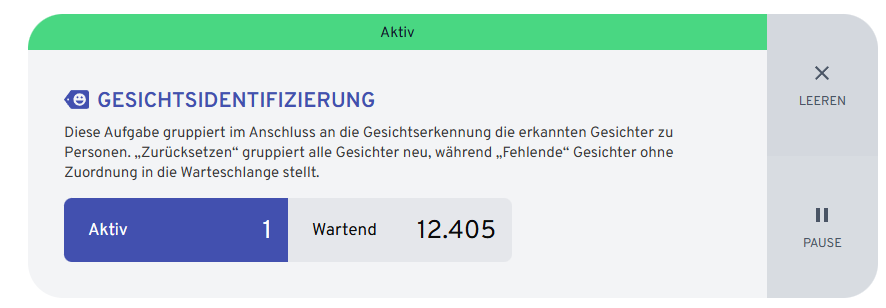
But my GPU is not used for Face detection, waiting 12.378 images, Active 1
Port is open (immich server)
sudo nmap -sT -Pn 192.168.178.107 -p 3003
11 Replies
:wave: Hey @palpatine,
Thanks for reaching out to us. Please carefully read this message and follow the recommended actions. This will help us be more effective in our support effort and leave more time for building Immich :immich:.
References
- Container Logs:
docker compose logs docs
- Container Status: docker ps -a docs
- Reverse Proxy: https://immich.app/docs/administration/reverse-proxy
- Code Formatting https://support.discord.com/hc/en-us/articles/210298617-Markdown-Text-101-Chat-Formatting-Bold-Italic-Underline#h_01GY0DAKGXDEHE263BCAYEGFJA
Checklist
I have...
1. :ballot_box_with_check: verified I'm on the latest release(note that mobile app releases may take some time).
2. :ballot_box_with_check: read applicable release notes.
3. :ballot_box_with_check: reviewed the FAQs for known issues.
4. :ballot_box_with_check: reviewed Github for known issues.
5. :ballot_box_with_check: tried accessing Immich via local ip (without a custom reverse proxy).
6. :ballot_box_with_check: uploaded the relevant information (see below).
7. :ballot_box_with_check: tried an incognito window, disabled extensions, cleared mobile app cache, logged out and back in, different browsers, etc. as applicable
(an item can be marked as "complete" by reacting with the appropriate number)
Information
In order to be able to effectively help you, we need you to provide clear information to show what the problem is. The exact details needed vary per case, but here is a list of things to consider:
- Your docker-compose.yml and .env files.
- Logs from all the containers and their status (see above).
- All the troubleshooting steps you've tried so far.
- Any recent changes you've made to Immich or your system.
- Details about your system (both software/OS and hardware).
- Details about your storage (filesystems, type of disks, output of commands like fdisk -l and df -h).
- The version of the Immich server, mobile app, and other relevant pieces.
- Any other information that you think might be relevant.
Please paste files and logs with proper code formatting, and especially avoid blurry screenshots.
Without the right information we can't work out what the problem is. Help us help you ;)
If this ticket can be closed you can use the /close command, and re-open it later if needed.
Successfully submitted, a tag has been added to inform contributors. :white_check_mark:@Mraedis thx

I don't see any enabled hwaccel config in your compose?
Start with the website template and don't follow chatgpt
i was also trying this:
https://immich.app/docs/guides/remote-machine-learning/
docker compose.yml:
and hwaccel.ml.yml
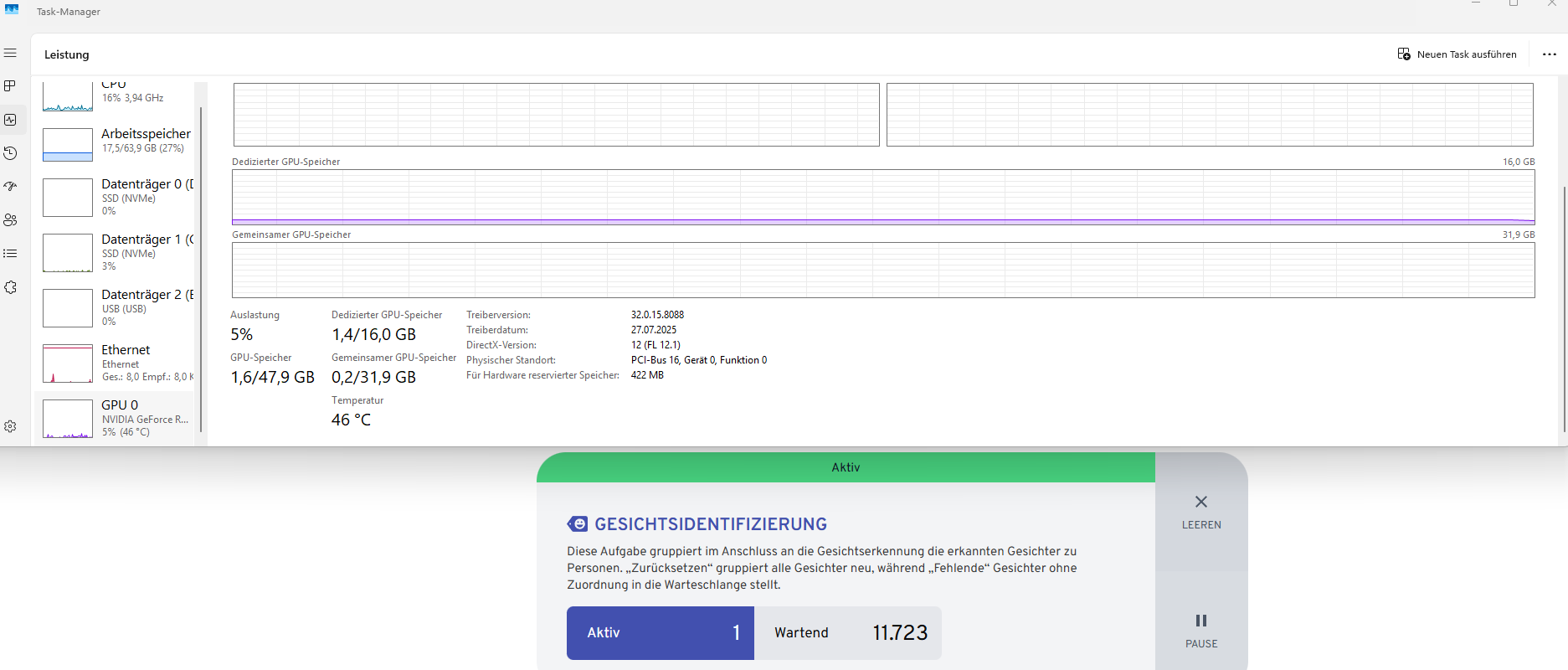
He is not using my GPU
Are you sure
Or did you just expect a higher usage %?
Don't forget the limiting factor here is the network/storage
I didn’t see any activity in my logs.
I know it was working on an older version in the past, and I was able to see logs back then.
I also tested directly from my Immich container:
So the Immich server is able to connect to my desktop PC on port 3003.
However, I still don’t see any logs.
My expected behavior is that I should see log entries inside my WSL container whenever remote machine learning is being used.
No actions
Try removing the internal machine learning url and see what's going on, maybe your container can't be reached?
mh, i was restarting the immich container and restart "INTELLIGENTE SUCHE"
Activ: 2 waiting: 93.667
wsl logs:
Now it looks like he is using my gpu / WSL
Im confused that my GPU is around at 1 - 10 % ussage.
My Server is using nvme and my desktop pc too. MY local connection is direct cat 7 and lowest iy my intel n100 CPU on Server side
All you need to pay attention to is the amount of requests it can parse/second
If going from normal to GPU-accelerated means 5/s to 50/s then that's 10x improvement
Don't try to 100% your GPU, it won't work
is there a way to check that remote ml is working ?
But nothing happened. I thought Remote ML would work. Is there a log that shows this information?