Huge RAM consumption after upgrade
Hiya!
Our CrowdSec LAPI had been running on 1.6.10 for a while, but our agents got upgraded to 1.7.0.
We've just noticed that there have been errors in the communication between the agents and the LAPI, as mentioned here in a few tickets already.
We upgraded our LAPI to the newest version and immediately the VM ran out of RAM.
After giving it more, we can see that crowdsec.log is just going absolutely bonkers.
Are alerts on the agent stored in memory when they can't communicate with the LAPI?
Could it be that the alerts that have been stored for over a week now, are now hitting the LAPI?
If that is the case, would restarting the bouncers help our case?
12 Replies
Important Information
This post has been marked as resolved. If this is a mistake please press the red button below or type
/unresolve© Created By WhyAydan for CrowdSec ❤️
For reference we have about a 100 bouncers connected to the LAPI, and it chewed through 6 gigs of RAM.
Now I've given it 12 gigs to test.
Are errors like this something to worry about or are they just because the LAPI is very busy?
We can also see this regarding the alert count (8:23 is when we upgraded)
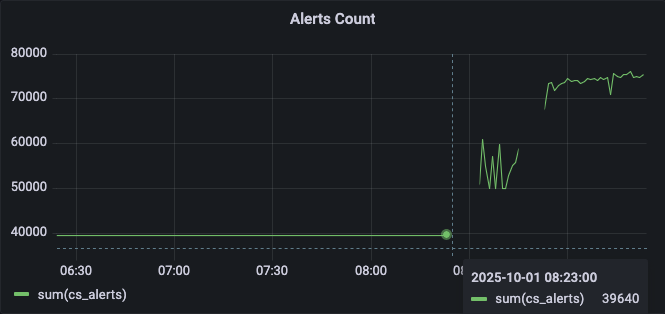
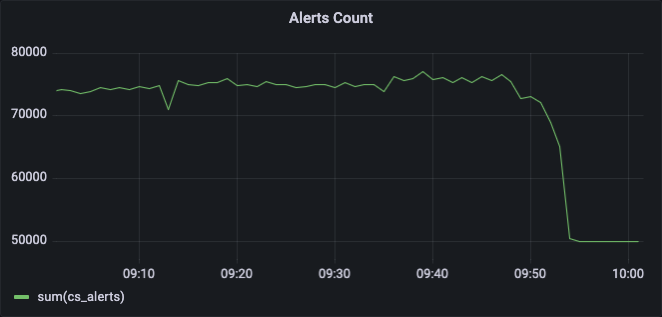
i restarted all crowdsec agents and we are back where we normally used to be
Is the Lapi upgraded to latest version as well? I remember we got these errors when upgrading agents first.
Sorry, read to quickly. I see now that you did
Hello,
Yes, crowdsec will buffer in-memory the alerts if LAPI is unreachable: we currently have an issue if LAPI is unreachable for too long, event processing will slow down a lot, which in turn might consume more memory (this will be fixed in 1.7.1 by making the push code completly non-blocking).
Regarding the error from the database, I saw that in the past when LAPI was receiving a huge number of alerts at the same (IIRC, i managed to reproduce this with a few hundreds alerts per second, which I thought was not very realistic but guess I was wrong :))
With the default configuration, 100 bouncers starting up and querying LAPI at the same time will consume quite a lot of memory, you can try to use the feature flag
chunked_decisions_stream, it should help memory usage
and what kind of communication error did you see in the agent logs before ?Glad to hear it is fixed in 1.7.1!
We'll check out chunked_decisions_stream, though normally the LAPI stays under 4 gigs of RAM usage, and doesn't consume much CPU either.
I guess that error is what we ran into then, but it is fixed now after restarting all agents.
The error we saw was this:
That said, when upgrading CrowdSec, do you recommend first upgrading the LAPI, and then the agents, or could that cause incompatibility issues as well?
With over a 100 machines, even though we of course use tools like SaltStack, we like to upgrade in batches in case something goes wrong, so it takes quite a while to go through all the machines.
LAPI shoould be upgraded first: agents might expect new endpoints/features in LAPI
and this specific error is because since 1.7.0, agents will compress their request to LAPI if it is bigger than 5kb, and LAPI before 1.7.0 did not know how to handle compressed payloads
Alright, that makes perfect sense, thank you very much!
I'm not sure how large our deployment is compared to others, but we always seem to find these edge cases that come from scale 😄
yes, for community users, it's quite large 🙂
We figured that would be the case 😄
I believe our machines made up quite a few of the victims of the latest "Nervous Burlywood Becard" attacks as well, as we've definitely had troubles with HostRoyale Technologies IPs in the past.
We are definitely quite happy with CrowdSec, and we thank you guys for the work that you do! 😄
Thanks for the help again!
Resolving Huge RAM consumption after upgrade
This has now been resolved. If you think this is a mistake please run
/unresolve