So constant Crashes, outages, errors, lag
So are you guys dying? Not using our money to upgrade? What's the deal? And When are you going to start crediting account for this abysmal service?
34 Replies
Yesterday I was waiting over 1 minute for Vllm to respond. from ANY datacenter. This is pretty shit to be honest.
We're happy to help you debug and provide refunds for lost time here on Discord or via email at
help@runpod.io. Naturally we only want the best, but admittedly it's been a rough week or so for incidents. Every case improves the platform significantly and we're alway around :)I'm not sure what you can debug ... it's a cached model and these stats are horrid. It's not even that big. sometimes (rarely) the response comes through with seconds... other times.. well... look for yourself over a minute cold start for a tiny model? 45 seconds to answer a query?

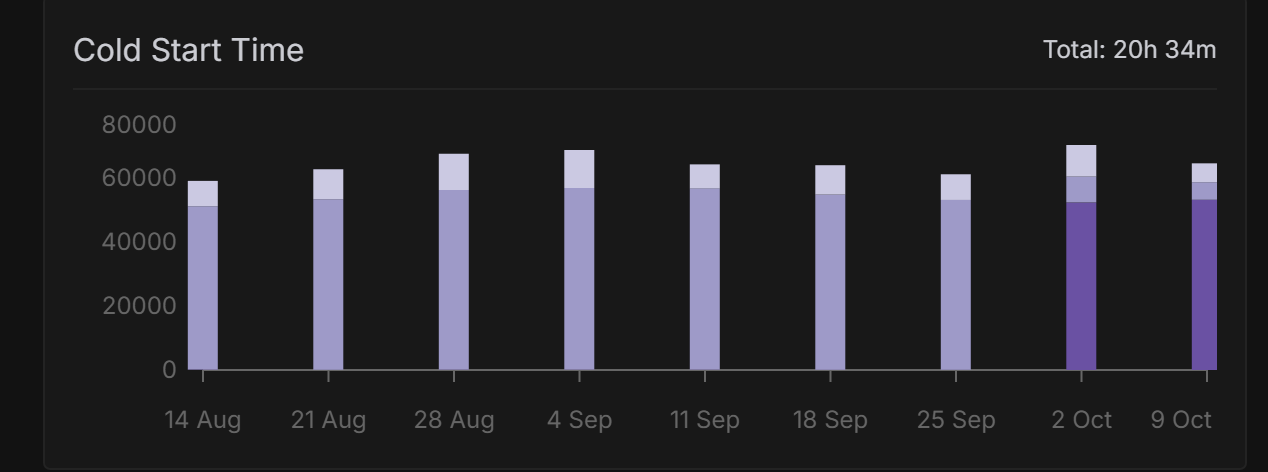
I mean I'm cool with a little cloud lag ... but when you have a difference between 1000t/s and 109.7t/s with the same model... same server ... moments apart ... that is unstable
I pay for GPUs and get CPU performance...
r9c1j91w5yd79z[info]INFO 10-10 10:27:05 [metrics.py:417] Avg prompt throughput: 109.7 tokens/s, Avg generation throughput: 0.9 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 5.1%, CPU KV cache usage: 0.0%.\n
INFO 10-10 11:50:30 [metrics.py:417] Avg prompt throughput: 1829.2 tokens/s, Avg generation throughput: 7.6 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 9.0%, CPU KV cache usage: 0.0%.
r9c1j91w5yd79z[info]INFO 10-10 10:26:18 [metrics.py:417] Avg prompt throughput: 1020.6 tokens/s, Avg generation throughput: 11.0 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 5.1%, CPU KV cache usage: 0.0%.\n
r9c1j91w5yd79z[info]INFO 10-10 10:37:08 [metrics.py:417] Avg prompt throughput: 1185.5 tokens/s, Avg generation throughput: 11.2 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 5.9%, CPU KV cache usage: 0.0%.\n
More of that awesome cold boot time...

Do you know how many people like to wait a minute for every response?
My logs around this are kind of weird, it looks like something prevented your pod from accepting jobs for a full minute. You have a custom image, can you share your handler? Let me see what I can do to help.
It's the standard handler from the runpod github. I baked the model in
I don't know anything about that handler other than it's probably terribly out of date and needs a lot of love >.>
I'll be back hopefully with an easy fix
Well yeah idkif that's the issue ... sometimes I get a good response, however like about 3 hours ago it was 90sec per query...
You shouldn't have to bake the model in anymore btw, https://docs.runpod.io/serverless/endpoints/model-caching#enabling-cached-models
Runpod Documentation
Cached models - Runpod Documentation
Accelerate cold starts and reduce costs by using cached models.
krisv99/vllm-latest:prod-Sushi
That's the image that's running if you want to look
pretty sure its public
cool will look at the doc thanks
it is a custom trained model. but who knows. I think it's on hf
I've changed gpu priority around as well.. but this wasn't great ..
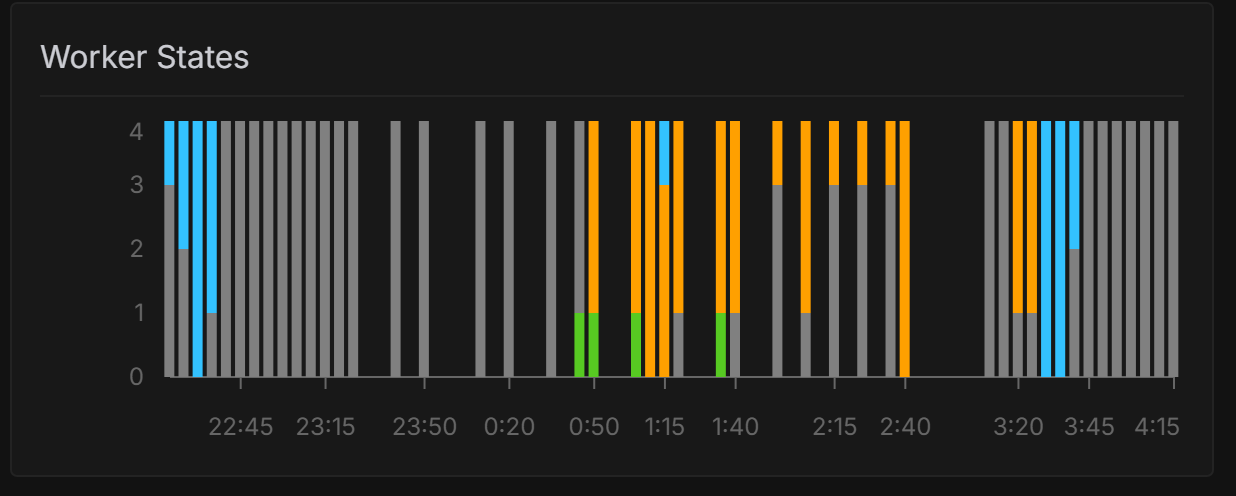
Unknown User•2w ago
Message Not Public
Sign In & Join Server To View

Unknown User•2w ago
Message Not Public
Sign In & Join Server To View
L40, L40S, and Ada's
If it was 1.5 minutes of think that'd be sweet ... But again ... half the time it's fine .. the other 50% my workers get "throttled" 4/5 in fact ...
Vars ... nothing special...
HF_TOKEN="{{ RUNPOD_SECRET_HF_TOKEN }}"
OPENAI_SERVED_MODEL_NAME_OVERRIDE=Lusty_chat
SERVED_MODEL_NAME=Lusty_chat
TRUST_REMOTE_CODE=true
MAX_MODEL_LEN=32000
Again I wouldn't complain if it was shit 100% of the time... but 80% of the time sucks.
There should be a defined threshold for how many workers can be throttled for a given endpoint. If a worker remains throttled beyond a certain duration (e.g., n minutes), it should automatically be terminated and recreated using a different available GPU type.
This approach would improve scalability and reliability in production environments. Runpod could maintain a clear separation between Development (Dev) and Production (Prod) environments.
By default, all deployments would go to the Dev environment with the current functionality unchanged. To upgrade an endpoint to Prod, users could submit a request to the Runpod team, including their use case and the desired throttled worker threshold. The Runpod team would then review and approve or reject the request based on suitability and resource availability.
Unknown User•2w ago
Message Not Public
Sign In & Join Server To View
@here So another sidenote... I decided to give it the benefit of doubt, and deploy an endpoint as suggested by DJ with a cached model. I'm not 100% sure how long it's supposed to take to provision. But it's only a 20Gb model so I can't imagine long.
That being said:
This is 10-15 minutes after deployment... I'll leave it here for your enjoyment. But I don't think I'll be getting workers any time soon ... despite the GPUS selected... from ALL DS
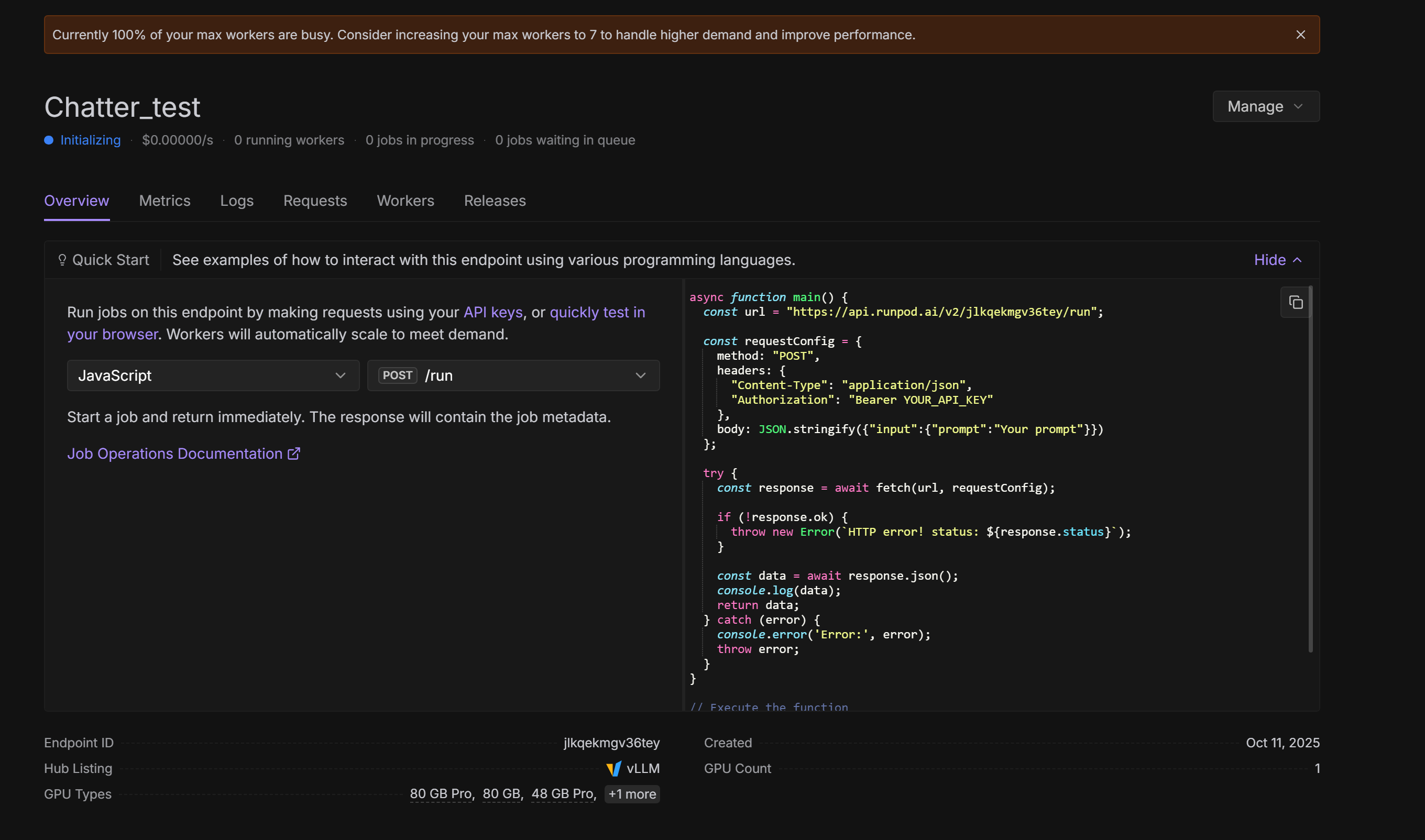
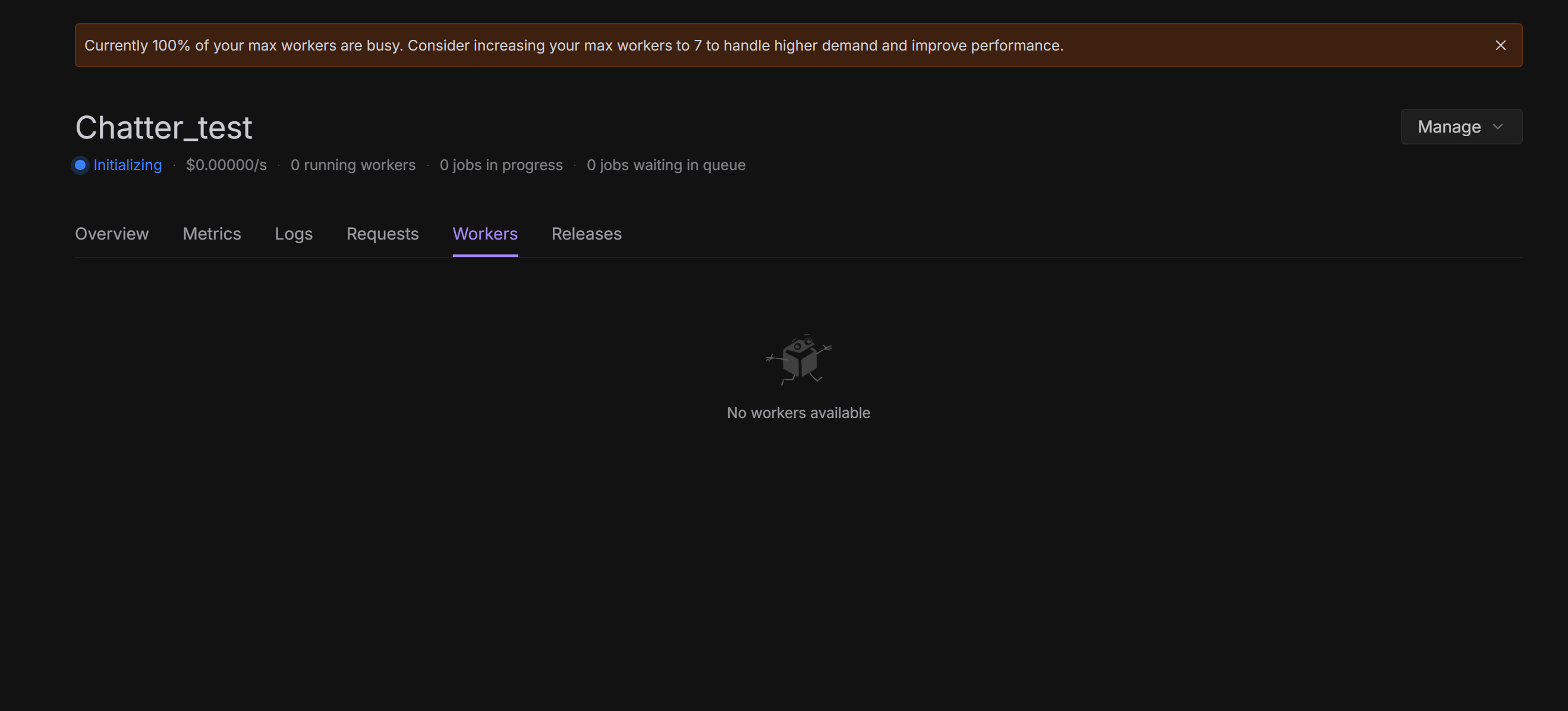
Unknown User•2w ago
Message Not Public
Sign In & Join Server To View
oh jeez
I cannot trigger a code deploy but I can wake someone up if I can figure out if this is widespread.
There are couple of bugs with this new Model Store feature as well. It's kind of developed keeping only LLMs in mind. And let's say the Huggingface repo has uppercase letters, see how it throws 500 errors. We need some better solution that works for all use cases and not only for LLMs.
I will add in very small print... right this second is one of those rare times that it's working perfectly ... last few query batches have been 10-20sec tops. This is why I feel I should get compo. When it's like this great .. when it's not I'm paying x4 as much...
And to mention again, the fact it's working right now means it's out of my control.
I've whined and complained in the past. And I admit that sometimes it's just me being a hot under the collar, and mistakes get made. I can own that, this project has had a huge amount of development. And I've been stressed out, so this time I did the research. I'm pretty sure I'm paying for poor performance that's out of my control. If I show this to my boss and it happens to be when it's taking 1.5 mins for a query I might lose my job ....
@here if anyone is tracking this now is one of those 45 second response times...
@here ok your new vllm release did nothing ..
engine.py :167 2025-10-14 03:29:53,833 Initialized vLLM engine in 401.45s probably worse...
401.45sec just to start the engine.... after which the query took 1sec.
@Dj Is this actually going anywhere or is it in the too hard basket now?
How is this a problem for me and not everyone else?
401s🐧

This seems like the amount of time it would take to download a model from HuggingFace. Give this a try:
https://docs.runpod.io/serverless/endpoints/model-caching
Runpod Documentation
Cached models - Runpod Documentation
Accelerate cold starts and reduce costs by using cached models.
Unknown User•7d ago
Message Not Public
Sign In & Join Server To View
This worker doesn't appear to follow the "load the model before the worker is ready" philosophy
GitHub
worker-vllm/src/engine.py at 2becd35345164ef5d567e1283ccfc65c2c25c1...
The RunPod worker template for serving our large language model endpoints. Powered by vLLM. - runpod-workers/worker-vllm
This is only called upon at startup and the handler doesn't have a mechanism to check if this is done or anything
I can double check this, however when I put the URL in th field it corrected it and removed the https:// section
That sounds right, we only need the name of the model from the URL so we parse it out.
However yes that was the intent... and it appears randomly that the worker stops responding and just sits there ..
So then I am doing it "correctly"
Take so long my chat client times out half the time.
P.S Not a dis... but I have a 1Gbit here at home at it takes about 45 secs to download the model. I would assume the Datacenter is at least 10 times faster...
engine.py :167 2025-10-14 20:45:14,777 Initialized vLLM engine in 66.48s
So yeah I didn't change a thing ... 3 minutes less at the moment.
@Jason @Dj So this is in the too hard basket now?