Serverless Worker Crashed but Request Still Running
A serverless worker suddenly died. However, an inexplicable phenomenon occurred — the request is still being processed.
Endpoint ID: h10qsr3s6f5puk
Request ID: 1c30dc85-d5e4-472d-b5e8-034d40249e7c-e2
Worker ID: 01yuqqrddjl88x
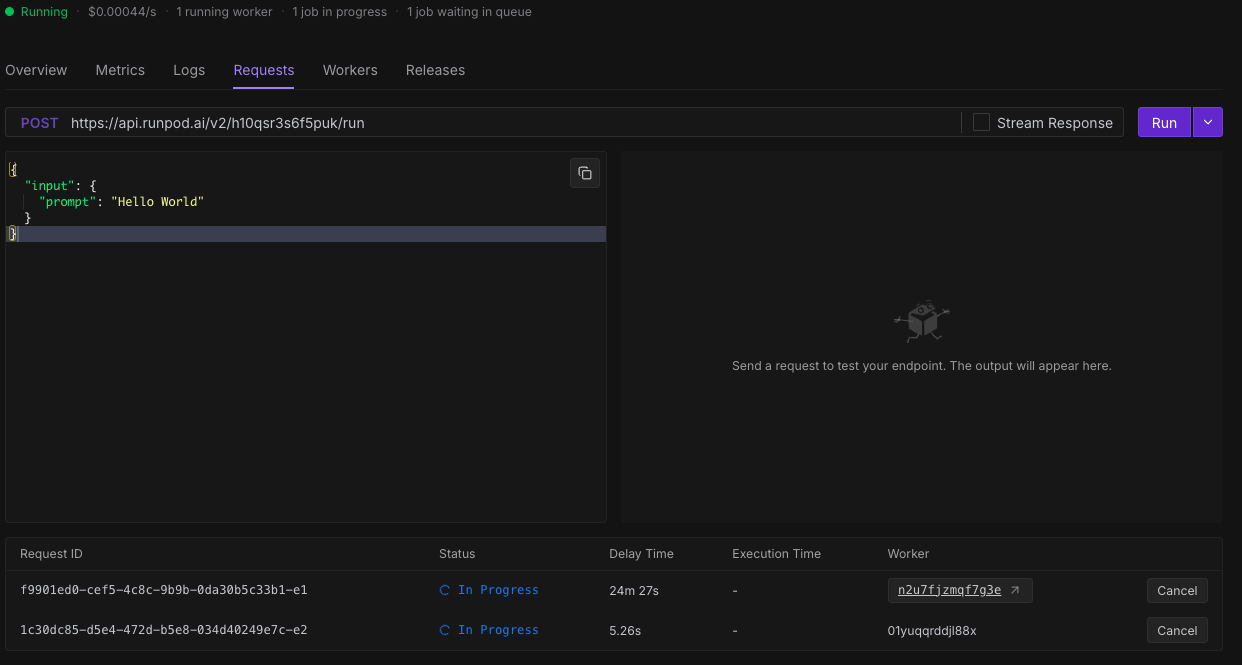
1. The worker suddenly stopped processing.
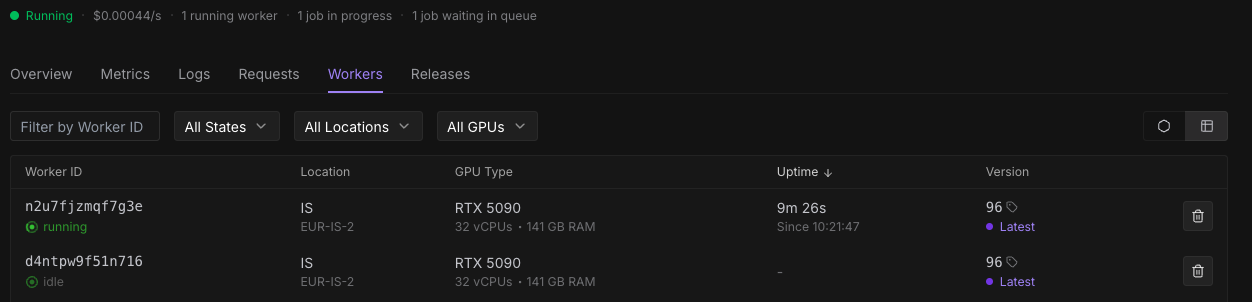
2. A strange phenomenon was observed on the Runpod management dashboard.
3. At the bottom of the screen, two “In Progress” indicators are shown, but at the top, it displays “1 Worker, 1 Progress, 1 Queue,” which is inconsistent.
4. The worker “01yuqqrddjl88x” at the bottom of the screen is grayed out and no longer appears in the worker list.
5. However, it is still continuing to process tasks at this very moment.
This issue is still ongoing. Please investigate immediately.
Endpoint ID: h10qsr3s6f5puk
Request ID: 1c30dc85-d5e4-472d-b5e8-034d40249e7c-e2
Worker ID: 01yuqqrddjl88x
1. The worker suddenly stopped processing.
2. A strange phenomenon was observed on the Runpod management dashboard.
3. At the bottom of the screen, two “In Progress” indicators are shown, but at the top, it displays “1 Worker, 1 Progress, 1 Queue,” which is inconsistent.
4. The worker “01yuqqrddjl88x” at the bottom of the screen is grayed out and no longer appears in the worker list.
5. However, it is still continuing to process tasks at this very moment.
This issue is still ongoing. Please investigate immediately.