GPU Detection Failure Across 20–50% of Workers — Months of Unresolved Issues
Hey.
This is becoming ridiculous. I’ve been having recurring issues with your platform for months now, and things are only getting worse.
I’ve already sent emails, opened multiple Discord threads, and every time it ends the same way — someone acknowledges there’s a problem (“ah yes, we have an issue”), and then support completely disappears. No follow-up, no fix.
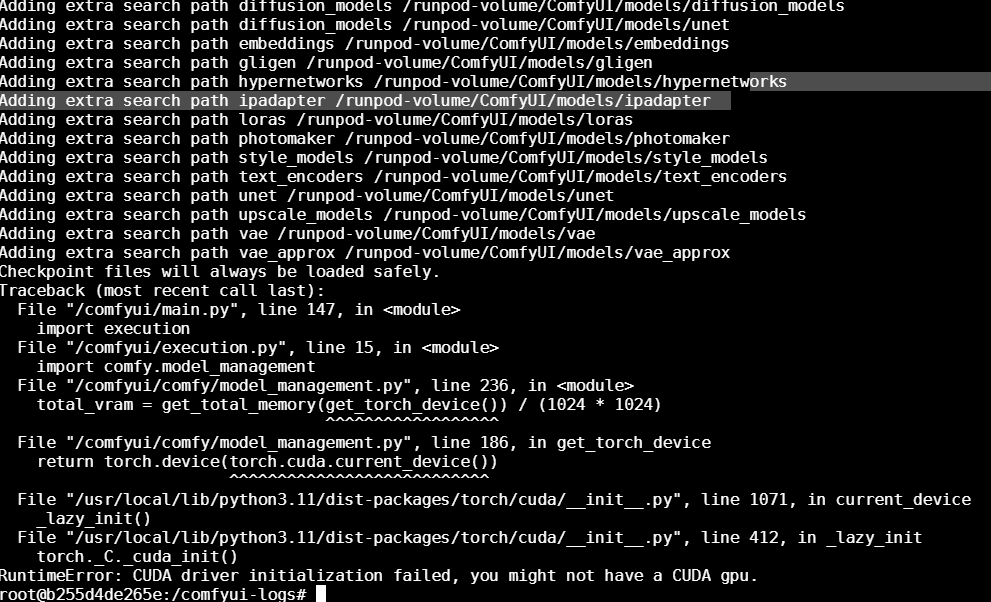
Right now, around 20% of my serverless workers and 50% of my pod workers (with 5090s) fail to even detect the GPU.
And it’s not just new deployments — even older endpoints I haven’t touched for months are now showing the same problem for no reason.
Yet these broken workers still run and get billed as if everything’s fine.
At this point, I really need a proper answer and a real fix, not another acknowledgment that goes nowhere.
some workers: hrrlqaxc0ypjfw / anqfwfwcy6xl2y / d4ltn8919nuo0q
4 Replies
@WeamonZ
Escalated To Zendesk
The thread has been escalated to Zendesk!
Ticket ID: #25331
Hmm?
It worked fine for me yesterday
Total 280 5090 pods only 4 failed
And they were on community cloud
Btw those errors did happen to me
@riverfog7 I'm only using secure cloud and serverless
And this happens multiple times a day when booting
And in my dev serverless worker, it happens up to 10 times a day. On a single endpoint. On 2 max workers...
-----
By the way, when this happens the worker stays UP EVEN AFTER THE TIMEOUT LIMIT, AND is being charged
did you open a ticket?
maybe support has something to say about it
contact them with the pod id (or worker id) of the problematic machine
as a workaround you can explicitly kill the worker if it fails to detect a cuda gpu
https://ptb.discord.com/channels/912829806415085598/1414830813127770152/1428632653946687540
as mentioned here workerid = podid
runpodctl remove pod ${RUNPOD_POD_ID}
works with serverless workers too