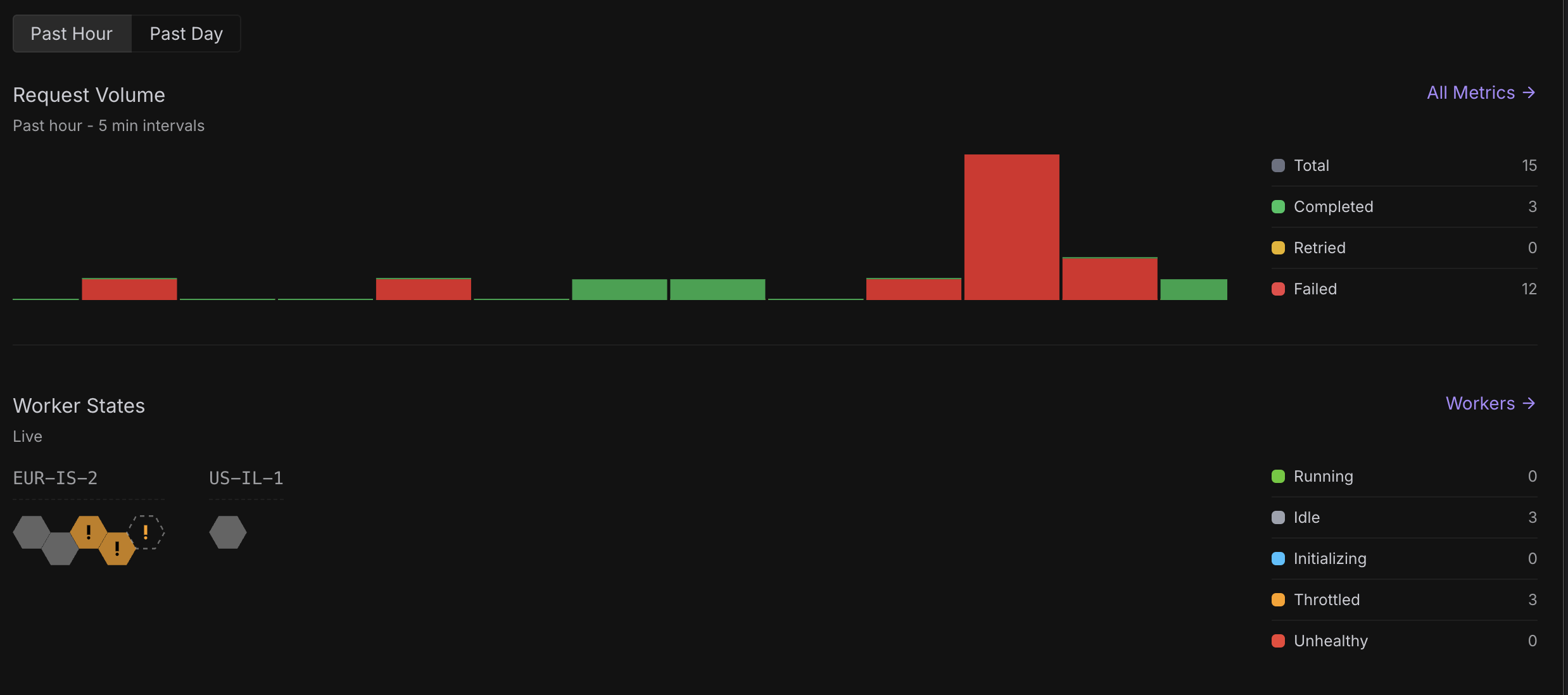
Failing requests
Hey, all of my serverless endpoint requests are failing. I’ve tried every available GPU config (24GB, 24GB PRO, 32GB PRO, 80GB PRO, 141GB) and they all show “High Supply”, but nothing is processing, the entire service is effectively down.
This has been going on for a while now and there’s zero communication. If there’s an outage or scaling issue, please just say it, so we can stop waiting and plan accordingly.
Can someone from the team confirm what’s happening and whether there’s an ETA on a fix?
edit: endpoint ID = uv7fieonipxw1q
This has been going on for a while now and there’s zero communication. If there’s an outage or scaling issue, please just say it, so we can stop waiting and plan accordingly.
Can someone from the team confirm what’s happening and whether there’s an ETA on a fix?
edit: endpoint ID = uv7fieonipxw1q