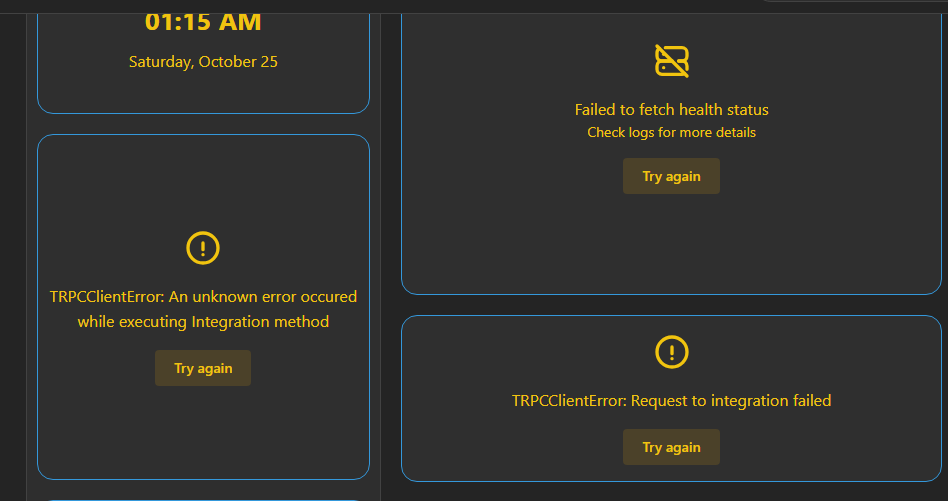
Recently after the latest update i have started getting the TRPCClient errors on the dashboard
the logs are attached in the message and this is just for a single integration.
I think this is a dns issue and the machine i run homarr on is actually my local dns server idk what exactly is wrong with dns all of a sudden but i need some help
I think this is a dns issue and the machine i run homarr on is actually my local dns server idk what exactly is wrong with dns all of a sudden but i need some help