Fail to crawl paper information from the OnePetro website,return statuscode 403
Actually, when I use firecrawl, I try to crawl the paper information on the onepetro website (such as abstracts, etc.), but I found that the return status code 403 is returned when using the self-hosted mode, but it works normally when using the API. The curl code is the same, what could be the reason for this?
Curl: curl -X POST https://api.firecrawl.dev/v1/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' ...
Cursor instalation
Hello guys,
How to install FireCrawl on cursor? Is there any detailed guide?
Thank you so much...
/map
I'm strongly considering migrating this process I've built to firecrawl. A general overview of what I'm trying to do: use firecrawl to obtain links when I perform a specific google query with /map. Pass the filtered links back to firecrawl's /scrape endpoint. However, what I'm noticing is that /map returns none of the links I see when I actually perform the google query. I'm getting back around 3K links from /map and none of them correspond to any links you'd see when you search that exact query up on google manually. All the links are the various links that come up whenever you search something, but isn't part of the actual search if that makes sense. For example: http://google.com/intl/zh-CN_cn/admob/landing/sign-up-002.html
http://google.com/intl/es_es/admob/announcements.html
http://google.com/intl/it_it/admob/businesskit/from-an-idea-to-an-app
Is my usecase incorrect? I...
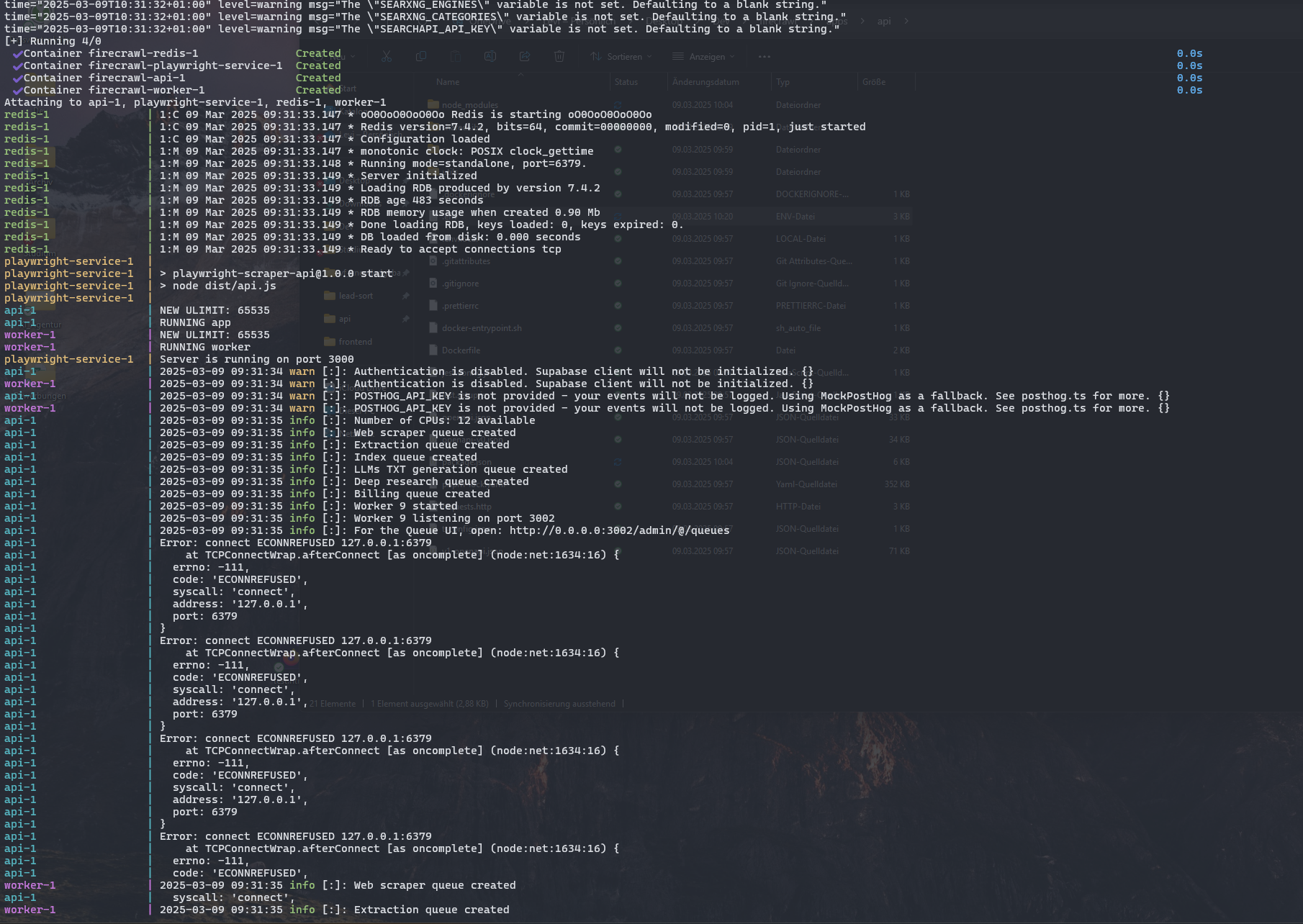
Run Firecrawl locally with "docker compose up"
Hey everyone! 😄
I followed the instructions from https://github.com/mendableai/firecrawl/blob/main/CONTRIBUTING.md
but when i run docker compose up, i always get the error in the image below.
...
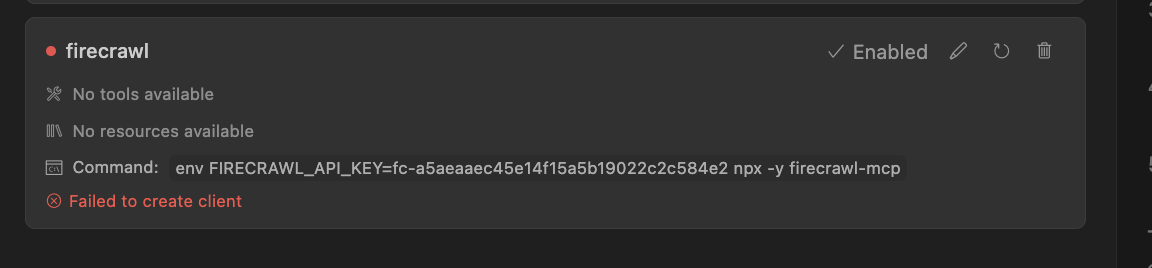
Failed to create client as a MCP server
Hello I'm using cursor 0.46.10 and i'm trying to add firecrawl as a MCP server like this
name: firecrawl
type: command
command: env FIRECRAWL_API_KEY={API_KEY} npx -y firecrawl-mcp...
Can't accept connection issues
Hi team @Adobe.Flash when I was running firecrawl locally, the workers keep posting errors when the server is running. And the crawled data is empty. How can I fix this?

/extract failed on self host
Hello,
I'm testing the new endpoint extract, I added OPENAI_API_KEY in my .env with a valid key. However the job failed, why?
request :...
Getting 403 when calling the API from fly.io
The exact same curl call fails inside fly.io but works on my machine.
This is when ssh into the firecracker VM:
`curl -X POST https://api.firecrawl.dev/v1/scrape -H 'Content-Type: application/json' -H 'Authorization: Bearer fc-xxx' -d '{"url": "www.heise.de", "formats" : ["markdown"] }'...
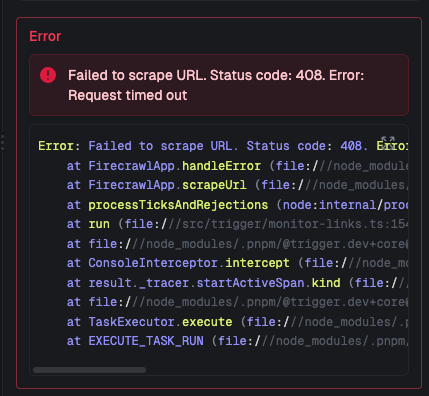
408 Request Timeout
Hi we are frequently getting these timeout errors after around 50 seconds. Any idea whats happening? Could it be a rate limit issue?
/Extract gpt-4o model returning error
I noticed that gpt-4o model often responds "error": "No valid URLs found to scrape. Try adjusting your search criteria or including more URLs.",
Sometimes it works and other times it doesn't. why does this happen?
Also the 4o-mini always kind of works but 20% of the output misses half the information and thus is very very inconsistent.
...
Include Only Paths and Exclude Paths not working as intended
Hi guys, I am using the Playground to do a simple Crawl on a single page and only get links with /buy/* , but the Include Only Path and Exclude does not work and filter down the links returned
Am I missing something?
crawl_result = app.crawl_url('https://www.propertyfinder.eg/en/search?c=1&fu=0&ob=mr', params={...
Pay-per-use
Hi, instead of charging base packages for /extract, do you plan to offer charges on a pay-per-use basis?
Getting extract values without Queue
Hey there 👋🏻 I am working on an AI workflow that uses the Firecrawl extract functionality as a Tool. It seems that if I now use the extract endpoint as described, it will return the job id and not the actual results. I could see the value of this in some scenarios, but in my case I am using the /extract endpoint for an LLM agent to consume, where it would make much more sense to have the request stay open until the extract job is finished. Otherwise, it adds unnecessary complexity where I have to instruct the LLM to wait and poll the /extract endpoint for the result. I am wondering if there is a workaround for this. Only thing I can think of is making a wrapper api around the extract endpoints, but for obvious reasons I want to explore other options.
Thanks in advance!...
/scrape contact info
Hi, is there a way to use /scrape to get contact information (socials, email, phones, etc.) from a url?
Reasons for Crawl to not see more pages?
Hello!
I'm trying to crawl a website and it's only reporting 12 pages when it should be way more.
Any tips on how to debug this or any gotchas I should be aware of?
Thanks!...
Handling POST-based pagination
Hi everyone,
I'm trying to crawl a list of questions, but the paginated index uses a POST request instead of GET, which complicates things.
How would you work around this issue?...
Error when use Scrape Endpoint
So I am playing around with the scrape endpoint and I keep getting:
The API still does not recognize jsonOptions, meaning that despite being documented, it is not supported in the current implementation.
Anytime I try to use the JSON format I get an error. Not sure why....
cost estimation of data pipeline
hello,
i am seeking assistance in building a data pipeline using firecrawl, specifically for consuming job post advertising data via the /extract endpoint. my goal is to process data from approximately 10 websites per day. for each extracted job post url, i intend to perform two primary tasks:
1. content extraction and classification:
• extract the job post content in markdown format....
Automate the scrapping of pages on my website using Make and Firecrawl
Hello,
I'd like to know how to automate the scrapping of pages on my website using Make and Firecrawl...
Efficiently syncing large data sets from different websites
Hello everyone,
I’ve been reading the documentation and would love to get your thoughts on how to efficiently sync a large amount of data between our database and a third-party website using the Firecrawl API.
For example, the Parliament website publishes records of recent meetings between MPs. There are a few hundred thousand meetings that I’ve already crawled and stored in our database using a custom CSS crawler. Now that I’m migrating to Firecrawl, I don’t need to crawl all of them again—I just need to check the main list for recent meetings and sync any that we’ve missed....