Main content extraction using API
Is there an equivalent of the 'Extract only main content (no headers, navs, footers, etc.)' from the playground, that can be used in the API scrape call?

Limiting results API is returning
Is it possible to limit the amount of characters from the Scrape endpoint api?
I'm getting an error that says the cell data I've recieved exceeds the limit that the platform I'm using can handle....
I'm having trouble getting playwright to run, only fetch works.
Hey, I'm having trouble getting playwright to work. Running Firecrawl locally.
I tried setting the
PLAYWRIGHT_MICROSERVICE_URL variable without the /html at the end, and then I get a 404 error.
I'm getting this messages in the console, What am I doing wrong?...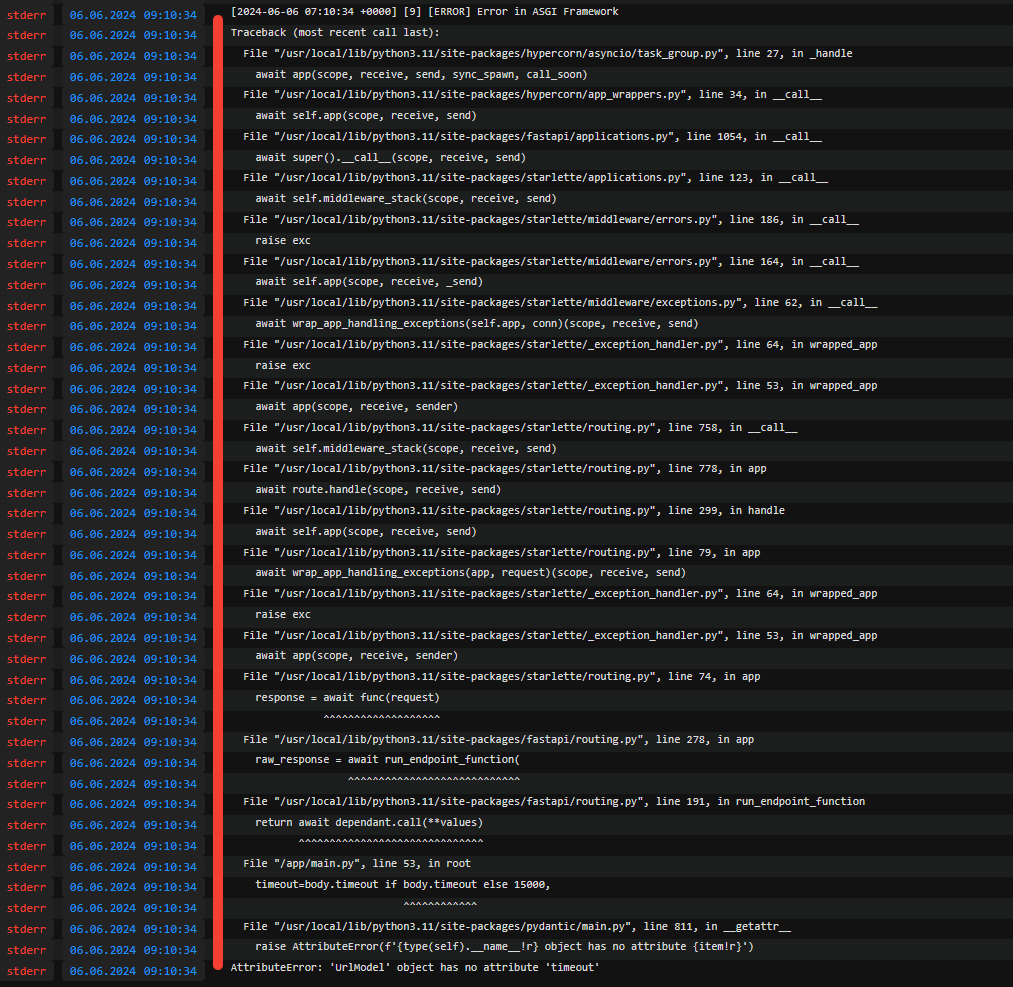
`crawl` results in `waiting` but `scrape` works
Hello, when running locally, I'm able to scrape, using curl, successfully.
However, if I try the crawl endpoint it results in a job that is constantly waiting.
Is this because it depends on scrapingbee? ...
Crawler Help
Hi, I am new here. I was wondering if any of you know how to get the full url from the links on a website. This is the code I have. The only URL that this returns is the URL of the page I gave it. I need it to be able to give me the full URL like this(https://recruiting.paylocity.com/Recruiting/Jobs/Details/2480999) of each job link on the site. My other pieces of code that I have wrote have only been able to give me this "/Recruiting/Jobs/Details/2480999". Thank you for any help or advice.
app = FirecrawlApp(api_key='FIRECRAWLAPI')
Set up the crawl parameters to return only URLs...
firecrawl seems to be timing out on all requests
https://api.firecrawl.dev/v0/scrape with any of the example inputs is timing out for me consistently.
https://firecrawl.betteruptime.com seems to indicate that the API is down. any help or details on when it'll be back up? I'm trying to evaluate various third-party scraping APIs and love that firecrawl is OSS but need a reliable hosted solution...firecrawl get intermediate pages
if firecrawl crawling fails at web page 50, firecrawl does not return anything. Is it possible to get the pages for the first 49 pages ?