Firecrawl
Join builders, developers, users and turn any website into LLM-ready data, enabling developers to power their AI applications with clean, structured information crawled from the web.
JoinFirecrawl
Join builders, developers, users and turn any website into LLM-ready data, enabling developers to power their AI applications with clean, structured information crawled from the web.
JoinHow can I use Firecrawl to crawl all the content from my Twitter search results?
Take a long screenshot
Scraping not returning with FIRE-1
Unable to scrape and extract data. Starts to Parallelise then nothing happens
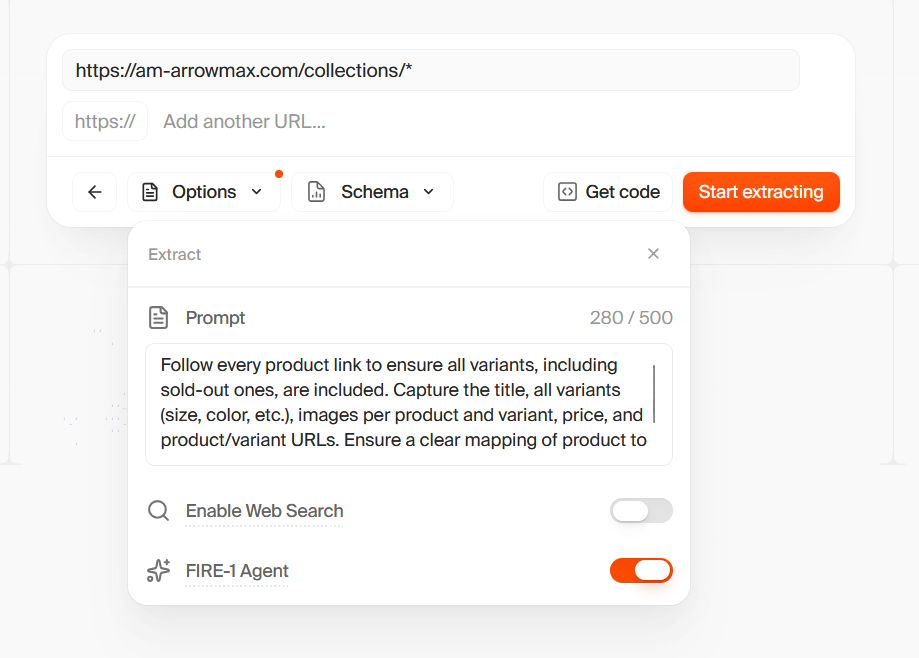
Follow every product link to ensure all variants, including sold-out ones, are included. Capture the title, all variants (size, color, etc.), images per product and variant, price, and product/variant URLs. Ensure a clear mapping of product to variants to images to price to URLs.
Follow every product link to ensure all variants, including sold-out ones, are included. Capture the title, all variants (size, color, etc.), images per product and variant, price, and product/variant URLs. Ensure a clear mapping of product to variants to images to price to URLs.
Country not supported in proxies
Help with scraping a paginated website using Firecrawl Actions
Simple hello world on Search returning error, missing "integration" parameter in payload
firecrawl.v2.utils.error_handler.BadRequestError: Bad Request: Failed to search. Invalid request body - [{'code': 'custom', 'message': "Invalid enum value. Expected 'dify' | 'zapier' | 'pipedream' | 'raycast' | 'langchain' | 'crewai' | 'llamaindex' | 'n8n' | 'camelai' | 'make' | 'flowise' | 'metagpt' | 'relevanceai'", 'path': ['integration']}]
firecrawl.v2.utils.error_handler.BadRequestError: Bad Request: Failed to search. Invalid request body - [{'code': 'custom', 'message': "Invalid enum value. Expected 'dify' | 'zapier' | 'pipedream' | 'raycast' | 'langchain' | 'crewai' | 'llamaindex' | 'n8n' | 'camelai' | 'make' | 'flowise' | 'metagpt' | 'relevanceai'", 'path': ['integration']}]
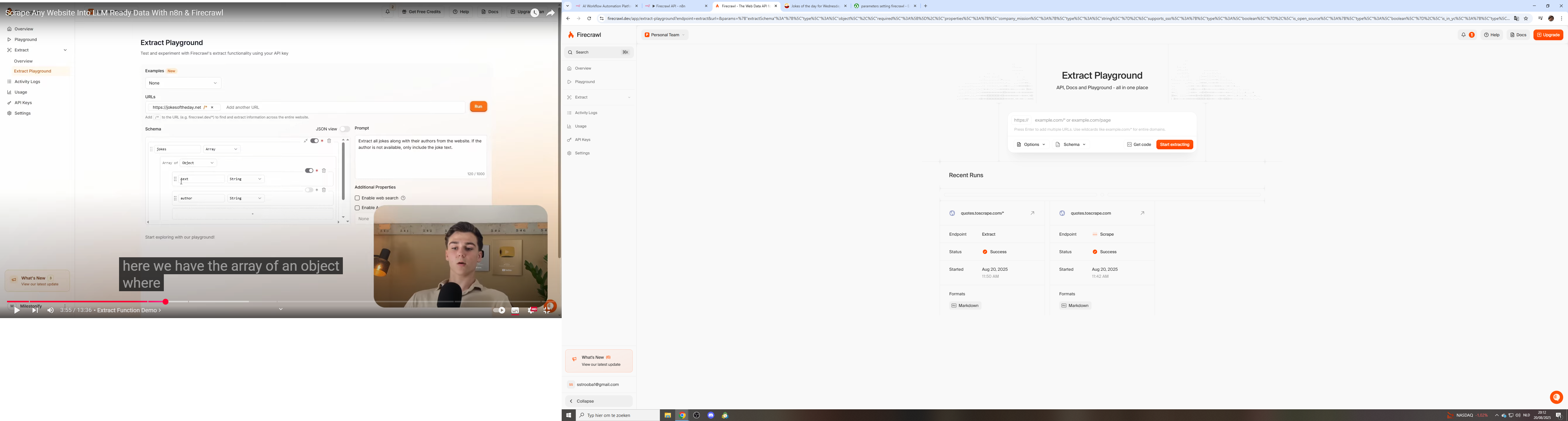
Extract playground returns expected results on web. API extract returns empty.
Help http request firecrawl v2 in N8N
firecrawlapp or firecrawl class help
Detecting Redirects
Got pydantic error when import firecrawl python v2
ID change between extract and get extract status
Excluding hidden elements from HTML or Markdown
display: none elements, and they are being included in both the HTML and the Markdown. Is there any way to exclude these?
Thanks!...Firecrawl seems to ignore URL hash fragments for pagination.
#start=N)
- Expectation (Playwright): total=15, page 0 -> 10 items, page 1 -> 5 items (selector div.result.lv_faq).
- Firecrawl scrape_url results: page 1 returns same content as page 0 or misses p.result_status entirely.
- Tried: formats=["html"], formats=["rawHtml"], wait_for=12000–20000, max_age=0 (fresh fetch), correct base URL from container to host.
...Building Chrome Extension
Search w/ JSON
Trouble extracting URLs from a JavaScript-based paginated search
Have a problem working with Firecrawl (im a beginner)