F
Firecrawl
Join builders, developers, users and turn any website into LLM-ready data, enabling developers to power their AI applications with clean, structured information crawled from the web.
JoinF
Firecrawl
Join builders, developers, users and turn any website into LLM-ready data, enabling developers to power their AI applications with clean, structured information crawled from the web.
JoinGlitch or Bug in n8n+Firecrawl Extract
Hey all. Really weird one here. My n8n workflow using Firecrawl Extract was working perfectly 2 days ago. Now, after using the Firecrawl EXTRACT node (and have tested this as HTTP Request node) , when the workflow then executes the next node, which is the Check Job Status Firecrawl node, it bizarrely changes the job ID which was passed as input from the EXTRACT node. Turns out it's weirdly triggering a new extract job in the previous node, and then using that new extract job id in the Check Job...
Firecrawl API consuming unstopped
Can someone helps me, My firecrawl API is being consumend but Iam not using it!!??
I am not using it and it is being consumed :((((((((((((...
Output like Apify
Hi, I'm using Firecrawl in conjunction with n8n to crawl some news websites. I was using Apify but gave up as their support was non-existent.
I was crawling news articles and the Apify node managed to give me the article body as a text field. It had all of the other links, widgets etc in separate fields and just the main article text of each site in a field named 'text'.
When i attempt to get the same output with Firecrawl, I'm getting differently named fields for different sites, and a large amount of unrelated info in them. While I can use it, theres way more data to parse, as well as added complexity of differently named fields, and my AI agents will use 2-3x more tokens per site because of that.
Is there any way i can get Firecrawl to put just the article bodies in a field named the same way for each different website i scrape?...
Struggling with paginated sources - Firecrawl amazing for details, painful for lists
Hey team! Love Firecrawl for single page extraction (the JSON schema feature is amazing), but I'm hitting a wall with paginated list pages.
My use case: Monitoring Italian government tender dashboards that update daily. Need to track new tenders across multiple paginated pages.
The problem:...
why i use the proxy still can't crawl youtube
payload = {"url": url, "onlyMainContent": False, "formats": ["markdown"],"proxy": "stealth", "location": {"country": "US"}}
Crawling Website Issues with n8n
Hi all! I am having trouble crawling websites (from Google Sheets) looking for specific keywords.
Not using a main url. Here is an example: https://www.whitehouse.gov/presidential-actions/executive-orders/
Looking for keywords like:...
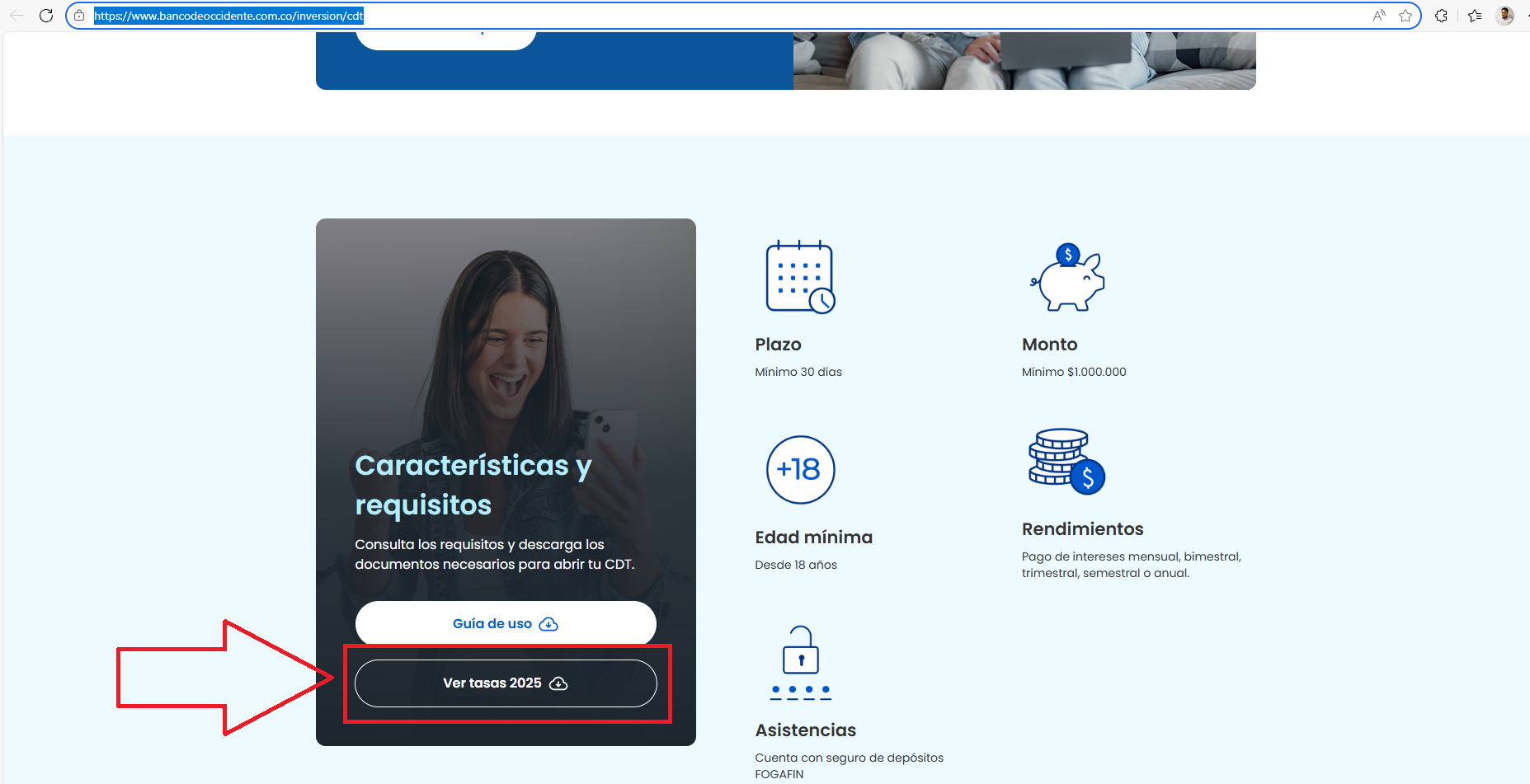
Question about PDF Scraping
Hey team 👋,
I'm working on a data scraping task and had a question about Firecrawl's capabilities for a specific use case.
My Goal: To extract interest rates for Certificates of Deposit (CDTs) from a bank's website....
Pricing Model
Sorry guys, I've really tried hard to understand the pricing model, but I'm confused by the overlap. I understood (maybe wrongly) that extract was like an upgraded / higher volume plan than Standard. I've paid for Starter Extract, but still I've exceeded my credits. Do I also need to upgrade my standard API subscription too to get more credits?
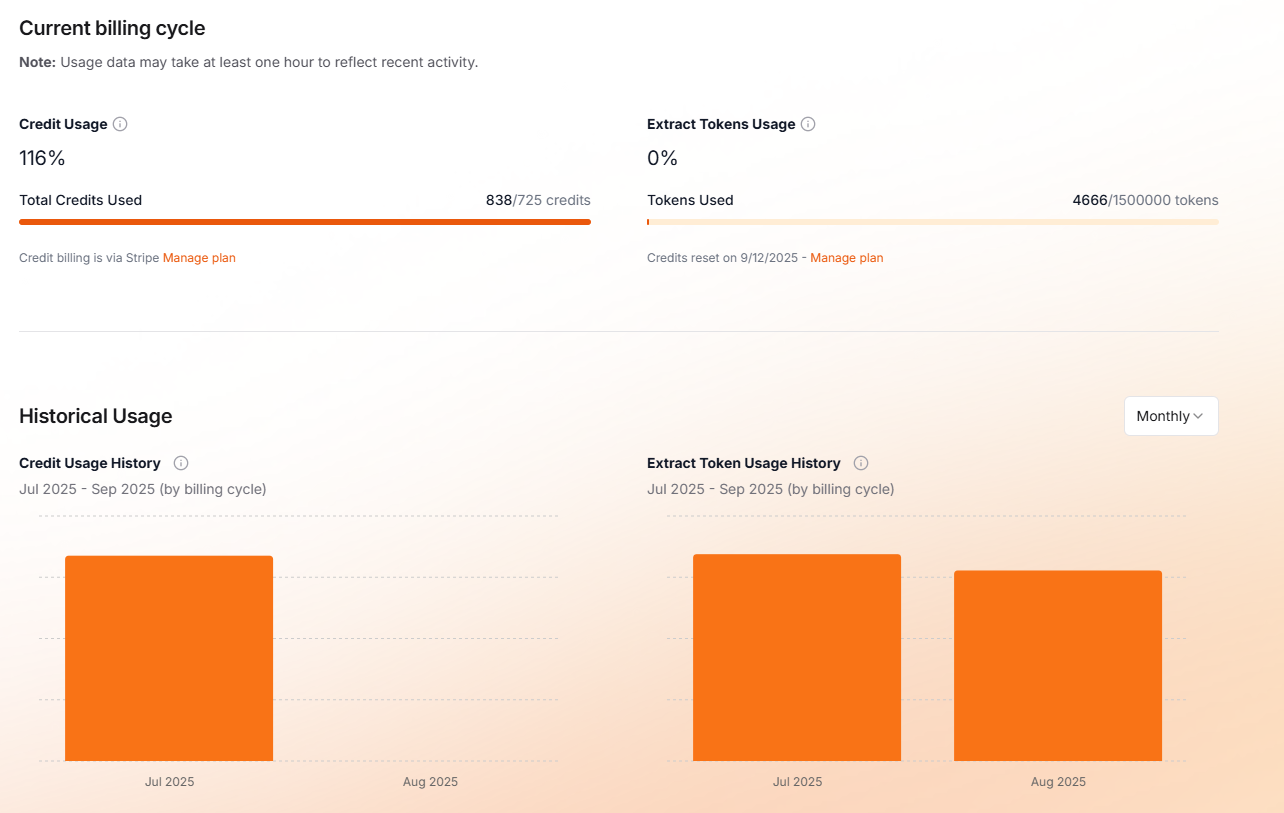
One Time Credit Purchase
I'm trying to figure out how to purchase credits. I'm on the Hobby plan and want to buy 2,000 credits for a specific project. However, the purchase page makes it sound like I'm signing up for a recurring monthly purchase. Is there a way to make a one-time purchase of credits to add to my current month's usage?
Firecrawl batch cannot crawl some urls
Hello everyone I am using firecrawl python sdk when I use batch_scrape_urls it can't crawl. Just 1 url is not successfully crawled it will logs error. I wish it will ignore the error url and execute the remaining urls. I have looked for the "ignoreInvalidURLs" attribute but can't find it in python sdk. here is my list of urls: ['https://www.britannica.com/biography/Stephen-Colbert', 'https://www.biography.com/movies-tv/stephen-colbert', 'https://www.cbs.com/shows/the-late-show-with-stephen-colbe...
Extract API - Captcha or Bot Solution
Guys, anyone know if Extract API has captcha/bot detect solution embedded? Because I'm trying to crawler a site and I received status success but the data of crawler was empty.
Can I cancel a subscription plan?
Could someone please tell me if I can cancel a Hobby or Standard plan at any time or once I start I have to pay the whole year monthly?
[self-hosted] Is there a way to get more logs or to change the logging level?
Is there a way to get more information on failed scrape requests when running a self-hosted firecrawl instance?
I'm often getting an error which is not very self-explaining (the scraped url is not broken!)
This is the full error message:
...
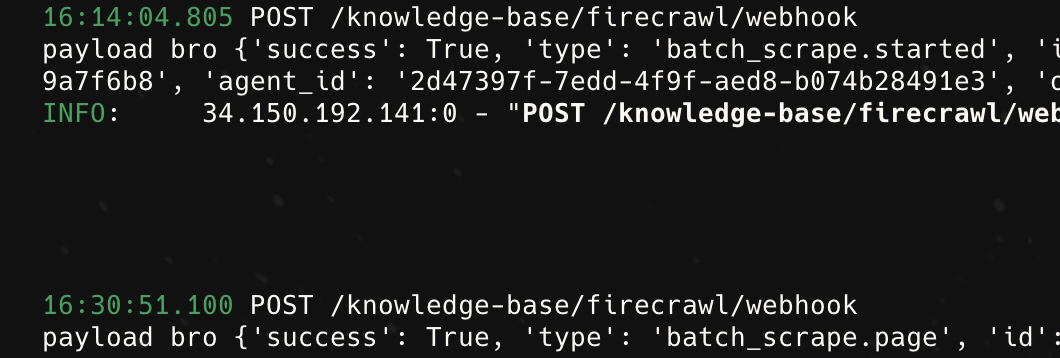
Batch Scrape Webhook
Hey,
I am unable to get the webhooks for batch scrape after getting the first one i.e batch_scrape.started.
getting this...
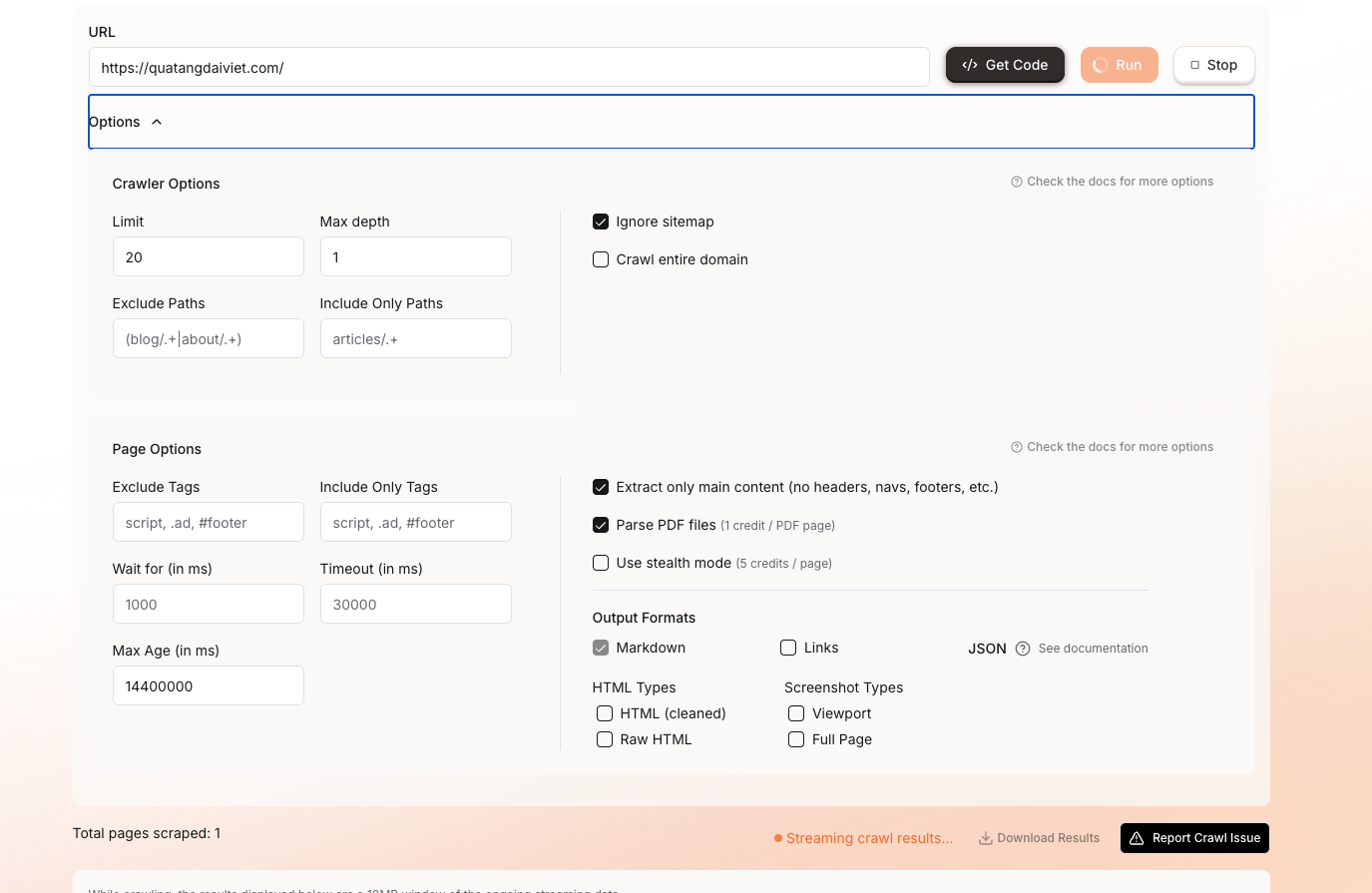
Crawl status tool is returning 500, need help to verify whats wrong with the request.
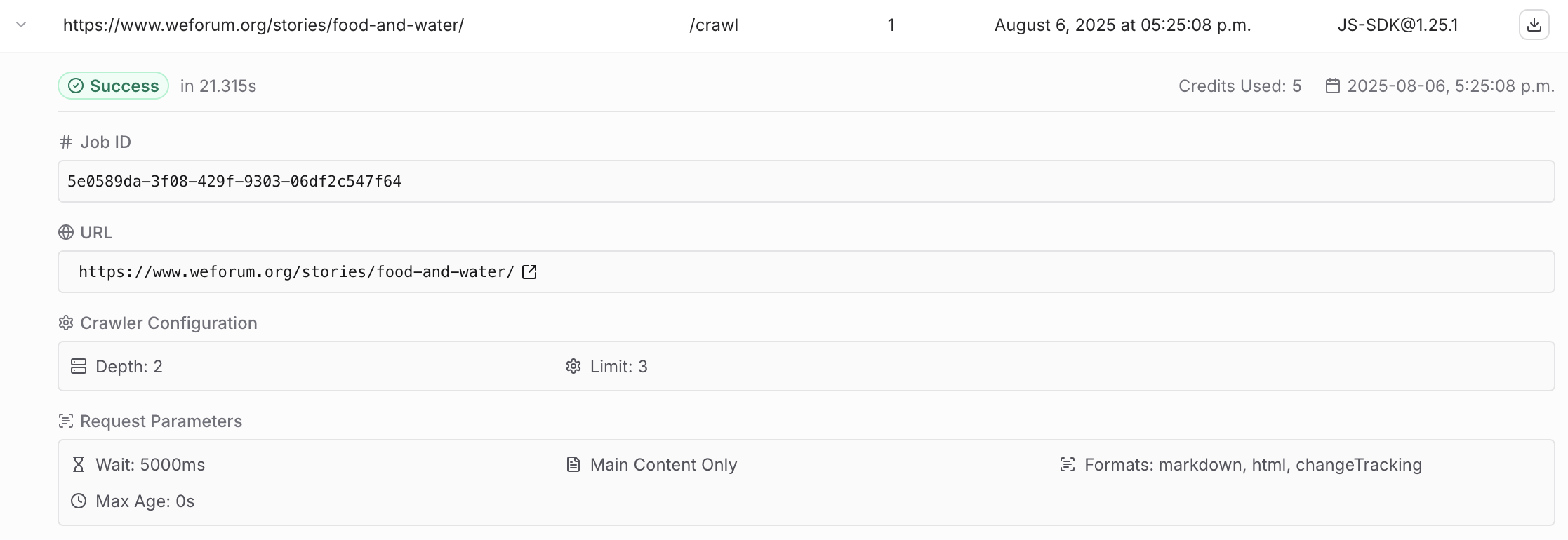
I am calling firecrawl_check_crawl_status tool in remote mcp with the following argument. {"id": job_id}. Acticity logs shows just one page being crawled although I set depth 2, limit 3. Posted a screenshot of activity logs (showing a different jobid). I have set a depth and limit but the log says one one page is crawl and 5 credit is used.
Response:
{'result': {'content': [{'type': 'text', 'text': 'Error: Failed to check crawl status. Status code: 500. Error: An unexpected error occurred. Please contact help@firecrawl.com for help. Your exception ID is 59b6e23c4a03481fa61b958c7b08c15c'}], 'isError': True}, 'jsonrpc': '2.0', 'id': 1754498520281}...
getting 404 error in trying to scrape reddit url
any one seeing the same "Error: Request failed with status code 403. Error: This website is no longer supported, please reach out to help@firecrawl.com for more info on how to activate it on your account. "
Keeps getting operation timeout when /scrape
Crashed at this
```
if (result === null) {
if (Object.values(meta.results).every(x => x.state === "timeout")) {
throw new TimeoutSignal();...