Testing default "hello world" post with no response after 10 minutes
openai/gpt-oss-20brunpod/worker-v1-vllm:v2.8.0gptoss-cuda12.8.1
runpod/worker-v1-vllm:v2.8.0gptoss-cuda12.8.1
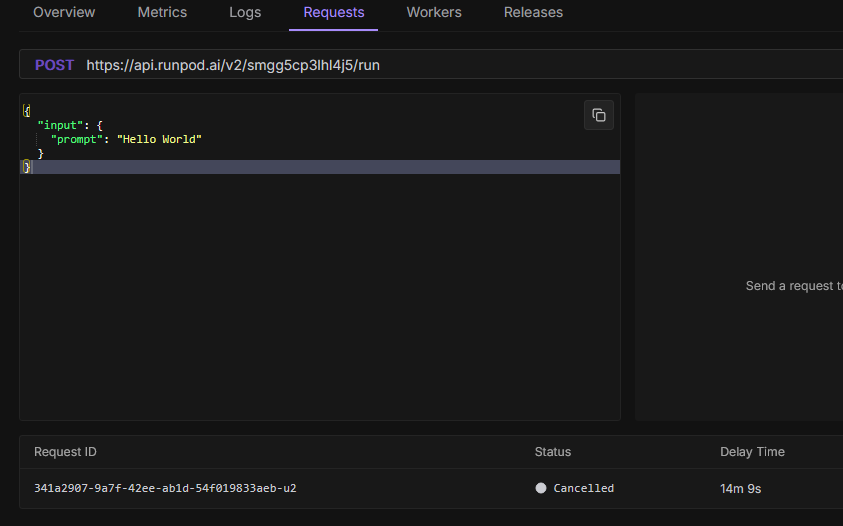
do the public endpoints support webhooks?
Serverless timeout issue
RunPod worker is being launched, which ignores my container's ENTRYPOINT
Load balancing Serverless Issues
Access to remote storage from vLLM
Cannot load local files without --allowed-local-media-path
..."allowed_local_media_path": os.getenv('ALLOWED_LOCAL_MEDIA_PATH', '/runpod-volume')
Add this line in:
/worker-vllm/src/engine_args.py
So you can add an ENV variable with the paths you want (or by default it will be/runpod-volume)...."In Progress" after completion

Load Balancer Endpoint - "No Workers Available"
/ping in order to prevent the worker to become "Idle", which is kind of annoying....a
Serverless Logs Inconsistant
long build messages don't wrap
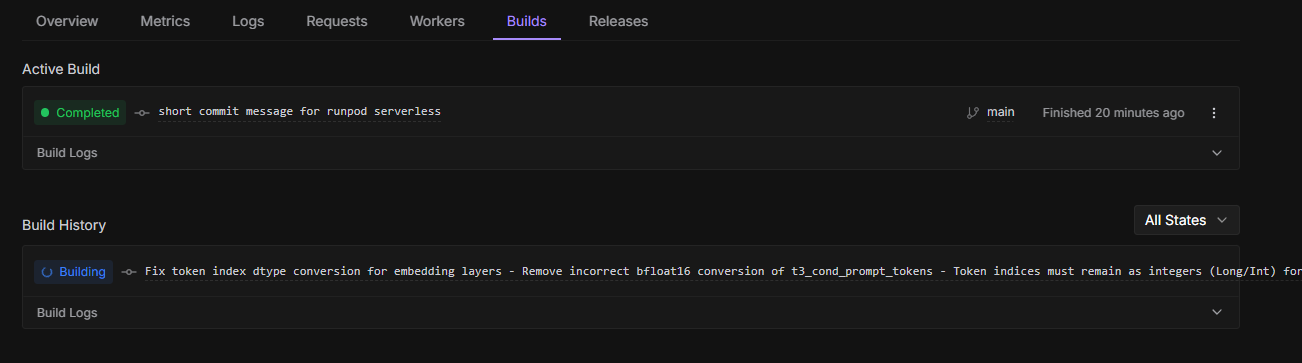
Failed to return job results
How to set max concurrency per worker for a load balancing endpoint?
Not getting all webhooks from requests
What are the best practices when working with network volumes and large models
Some questions about Serverless workers and custom workflows
Update Transformers Library
New Serverless UI Issue
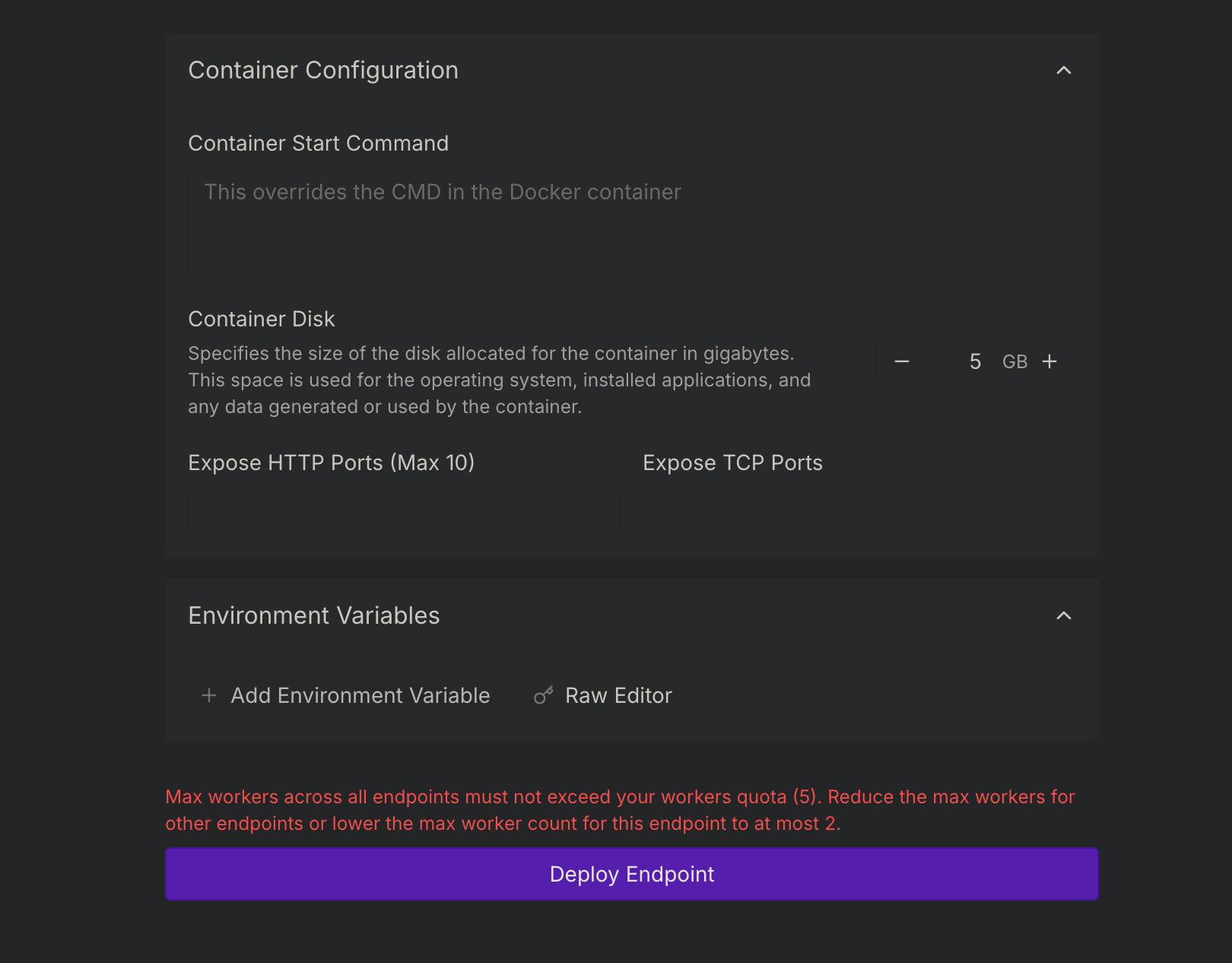
serverless runpod/qwen-image-20b stays in initiating
Serverless Load-balancing