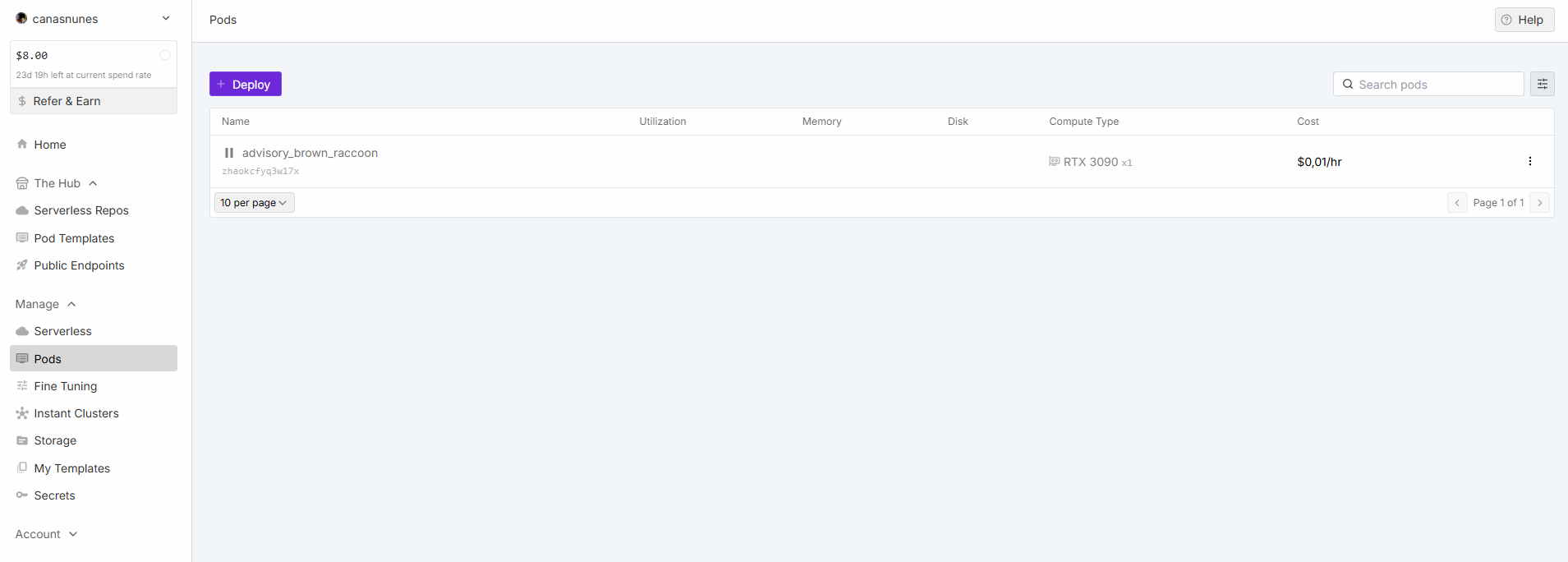
Change GPU on stopped POD.
8 x RTX 5090 PODs JupyterLab and Terminal not working
OutOfMemoryError: CUDA out of memory
gpt-oss-20b, llama-3.3-70b) on pods. Even when running GPUs with way more than the required vRAM (e.g., 141GB H200 for gpt-oss-20b) I still get this error. I have tried setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True but that didn't fix it.
[info] Pipeline stopped due to error: CUDA out of memory. Tried to allocate 42.49 GiB. GPU 0 has a total capacity of 139.72 GiB of which 38.96 GiB is free. Process 584678 has 100.75 GiB memory in use. Of the allocated memory 99.91 GiB is allocated by PyTorch, and 181.47 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)\n>...
Jupyter Console is Ready but cant connect
comfyuiUIWAN 2.2 haven't gotten the server running unless launched manually
Too many open files on GPU pod A6000

EU-RO-1 servercenter veeeery slow internet connectivity
is there any solution to check container is healthy?
ComfyUI fails to start on nerdylive/stableswarm:dev-29b04cfff834fa5cd02b319bf9103251be95ca80
Does it usually take this long to install Comfyui on the Swarmui setup?
nerdylive/stableswarm:v0.1.1-cuda12.6 It finished initializing though oddly enough swarmui setup is stuck on 3 out of 6 installing comfyui @Jason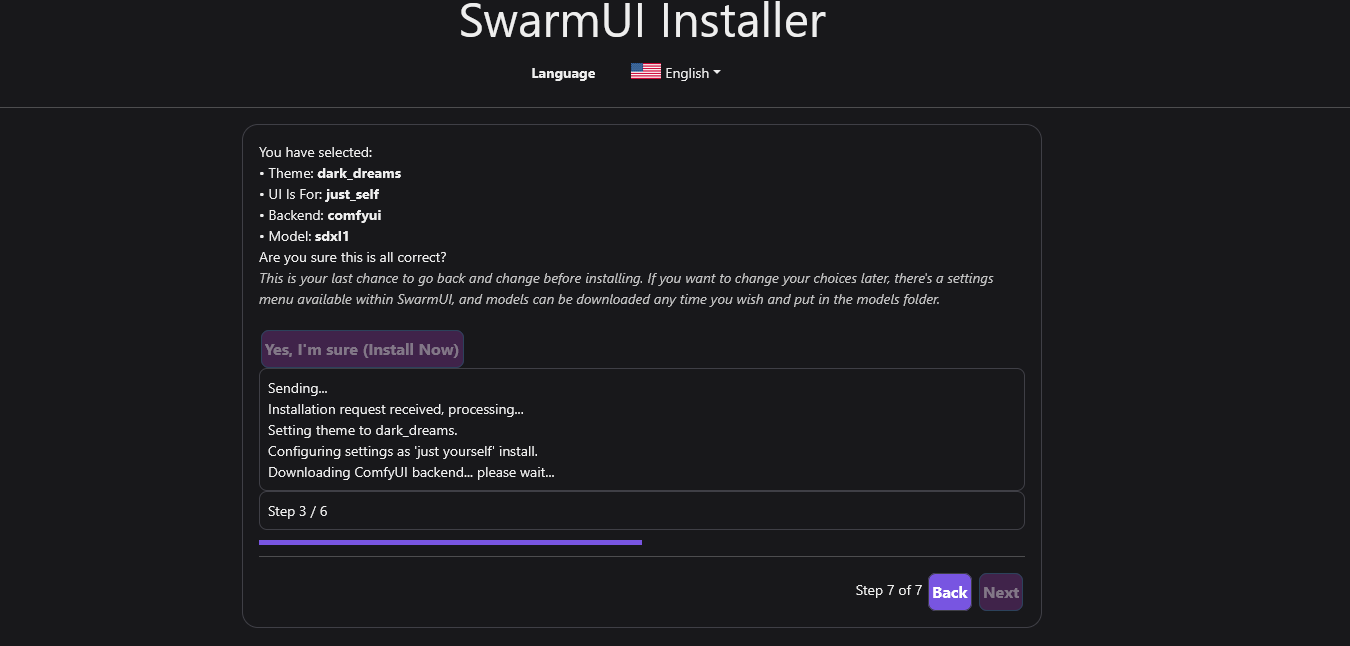
ComfyUI workflows takes hours on runpod
Disk quota exceeded error
Is it possible to run OpenWebUI on a pod?
RUNPOD_ALLOW_IP does not work
The US-IL-1 server is experiencing issues with connectivity and performance again
My images that were generated in 20 seconds went to 50 seconds per image. Has there been any change
Need help setting up vs code ssh
Overcharging
'd like to share my recent experience using the RunPod service to set up a ComfyUI environment.