US-KS-2 H100s Slow Network
Extremely slow network connection - basic ssh commands like cat, ls take several seconds.
Seems to affect only H100NVL, H100SXM, H100PCIes.
Could someone please investigate?...
Inconsistent Pod behavior
I'm running the same exact custom docker image on the same exact instance types. One pod always fails with a CUDA memory error, and the other pod doesn't. I am using the same exact setups for the pods, the same exact inputs, the same everything.
I have tried switching to use multiple different regions of pod, different volumes, etc. Behavior is still the same....
Multiple templates blocked
Multiple ComfyUI templates are not working currently as they all get stuck on
Installing pyOpenSSL...
One Click - ComfyUI Wan2.1 - Wan 2.2 - CUDA 12.8
Wan T2V-I2V-ControlNet-VACE For RTX 5090
hearmeman/comfyui-wanvideo:v9...Port is not up yet
Persistent "Port is not up yet" with docker.io/runpod/a1111:1.10.0.post7
on multiple community cloud 4090s. Issue persists over an hour of waiting...
Is US-IL-1 dead?
Really bad connections and consecutive pods deployed on US-IL-1 servers are showing bad stability with and failing. Running with better launcher [dev] template using ComfyUI.
Please check US-KS-2...Hanging
qwhsqs5v5whcda is running right now...but I won't waste credits much longer
My GPU disapeared from my Pod
I created a pod yesterday, I trained 3 models without probelm with the GPU TRX 5090, and I don't know why, but my GPU disapeared. I wanted to lunch a new training, but I saw that now my pod that was working really well with a GPU, only have a CPU now and it is written 0 x RTX 5090??? I didnt change anything, what happened??? Can I have my GPU back???
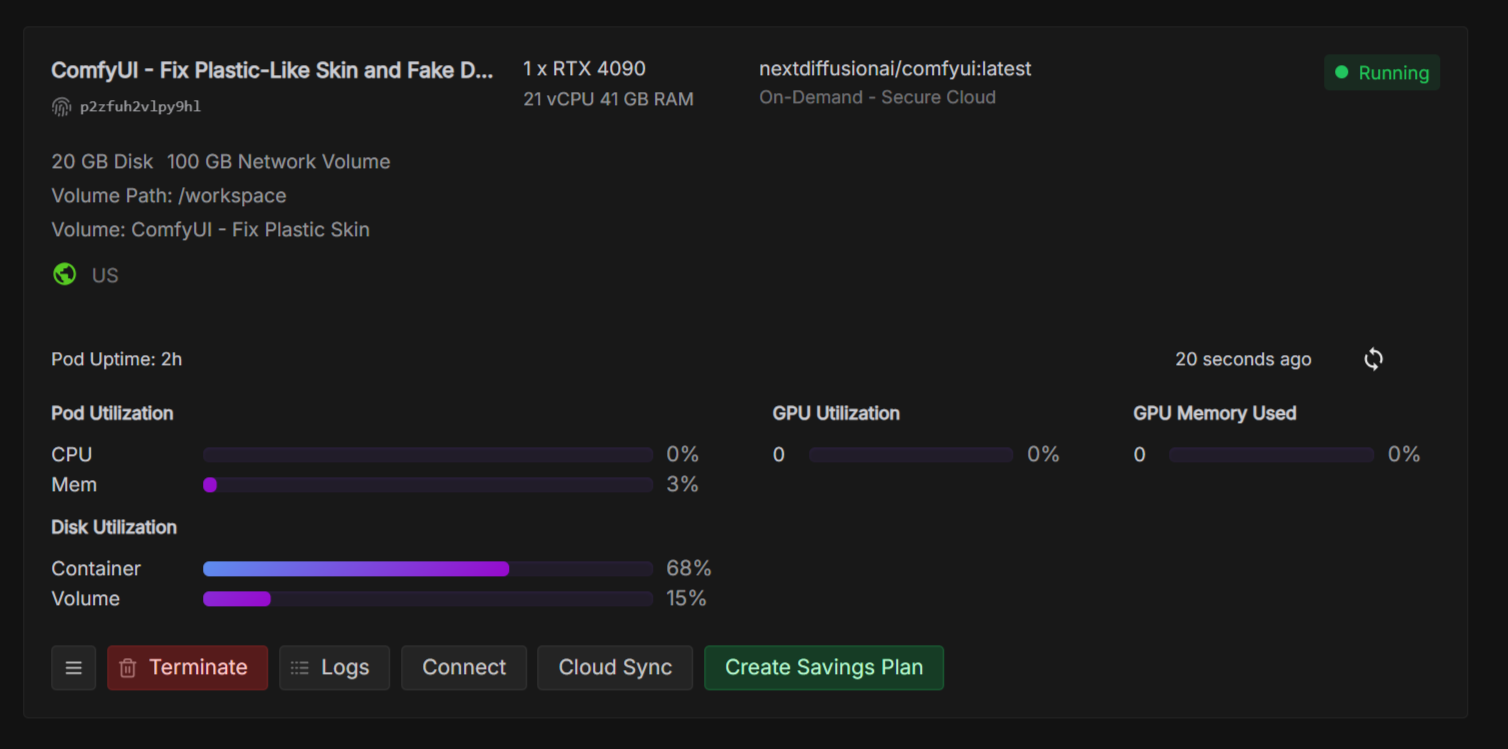
Missing environment variables on every pod
Is this just happening for me? Every pod I try and select has no environment variables
What's wrong with US-KS-2???
I've spent the last hour trying to successfully get pods up and running. The stats are showing 1% RAM usage...VERY SLOOOW response on everything.
Help me understand serverless pricing
So i've been trying the serverless functions to get a understanding on how it works. Been using a cheap one at $0.00016/s which i understand to be execution time + the idle time that you set on the workers. I noticed that while testing my serverless functions, i was seemingly getting billed multiple x's of what i should be based on the execution time in the metrics. Since my tests are only consuming fractions of cents at this point, perhaps theres just a floor im not aware of which causes it to bill more? Maybe some small hidden fees im not aware of? Anywho, based on execution time today i should have spent $0.05 but it currently sits $0.35 in the usage graph, but i have a screenshot from earlier today that shows my im down almost $1.. no clue where the rest of those cents went.
These are just pennies, however this does concern me if i choose to use serverless functions for my business. I want to understand whats consuming the money i've loaded into my account and whether its just penny fees, or whether this magic bill is going to scale with my load. My understanding was that i would only pay for execution time.
Edit: So cold start time is also counted. Still trying to get the math to work out...
Is US-KS-2 dead?
Like 3 days a row pods on US-KS-2 working awful. Running on PyTorch 2.4, 2.8, doesn’t matter. Like 10 minutes to load Jupyter through 8888
Issue with vLLM on L40s GPU on RunPod
Hey everyone,
I’m running into an issue trying to use vLLM on a RunPod instance. Here’s the setup:
Instance: L40s (4x GPUs), Ubuntu base image...
Memory(RAM) issues with pod and comfyui
The POD says 50 GB ram.. However, the comfyui says, i have 250 gb ram. Also, I get core dumped error, whenever, i use torch.compile or sageattention. I noticed this issues irrespective of the gpu configuration.
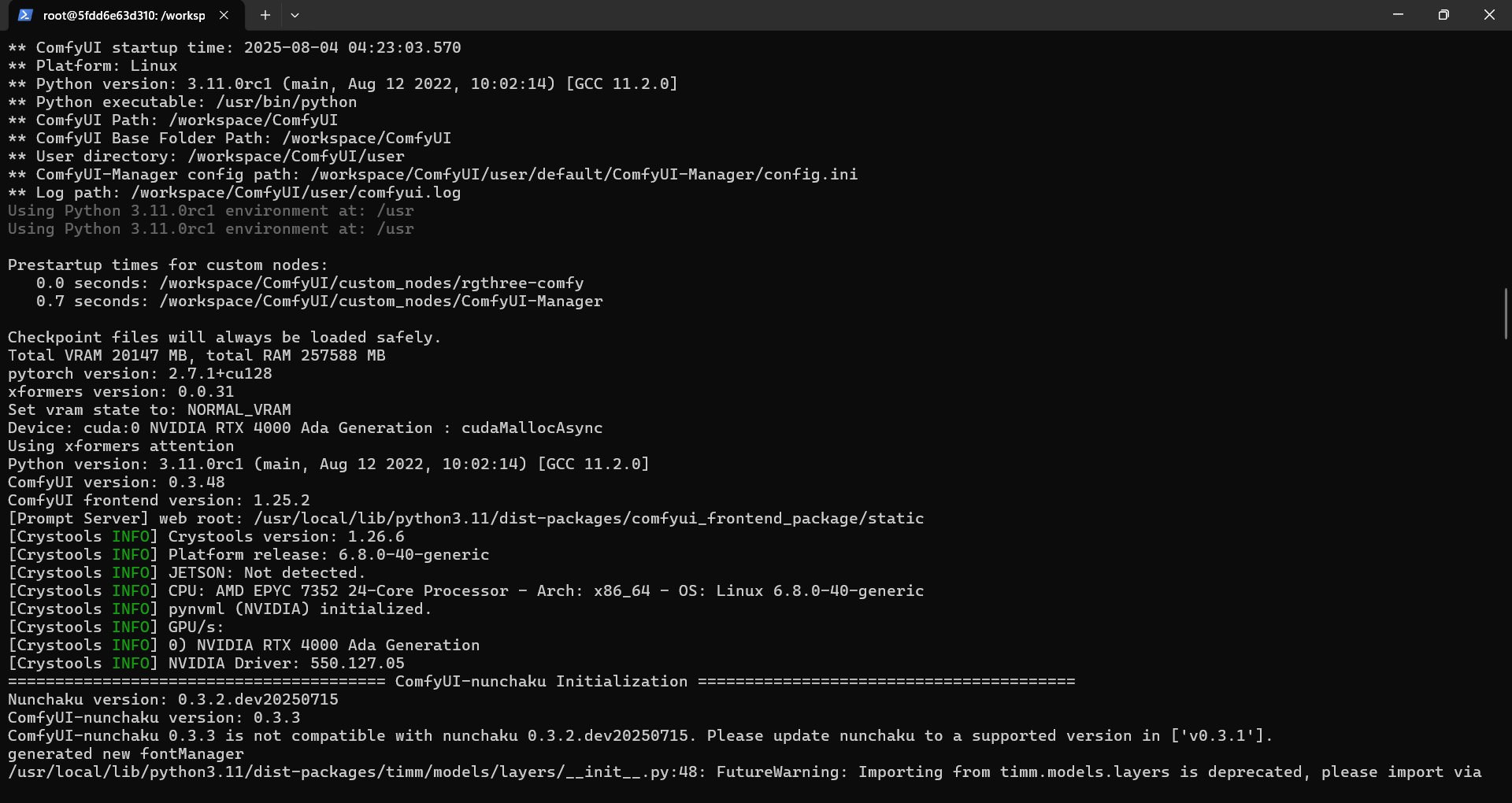
Error CUDA 12.8 GPU detection
Environment:
- RunPod GPU Instance (RTX A5000, 24GB VRAM)
- Ray Serve deployment
- Piper TTS model via ONNX Runtime
- CUDA 12.8...

🛠️ Fixing GPU Invisibility – CUDA 12.6 Upgrade Guide
If your system isn't using the GPU for TensorFlow workloads even though the hardware is installed and drivers are up to date, you're likely hitting a compatibility wall between your current CUDA version and TensorFlow.
This situation led to zero GPU memory usage, nvidia-smi errors, and full CPU fallback during training.
The attached .md file walks you through upgrading from CUDA 11.8 to 12.6, setting up the environment, and confirming TensorFlow is actually using the GPU. This resolved the issue on our end and restored full GPU acceleration....
ComfyUI no longer working?
Log just keeps spamming the attached.... the log file it is printing about is a completely blank file.
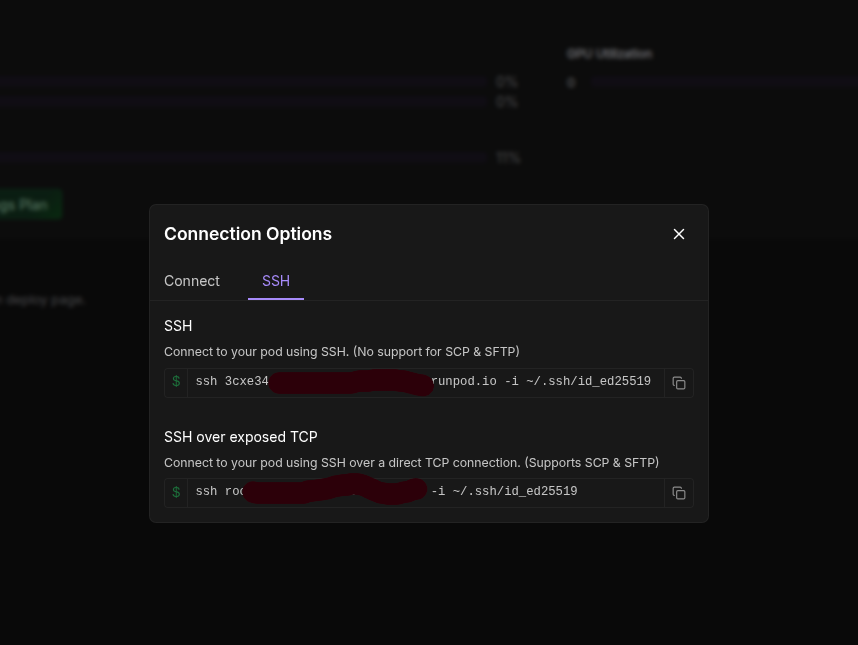
How to SSH connect to the runpod for uploading files?
I thought it maybe better to create a thread rather than spamming the global any further.
See attached image... I have got as far as being able to see this screen for connecting over FTP.
The problem now is, what do I do next? I tried copy and pasting the command in the second line into my linux terminal, and it just says "connection refused". See second image.
...
⚠️ GPU Not Utilized – System Defaulting to CPU Execution
Hey team,
We’ve identified a critical issue: the system is running deep learning workloads on CPU instead of GPU. After digging into it, the root causes include:
TensorFlow and CUDA version mismatch
...
H100 in US-KS-2 has high CPU latency
Hey, I just reserved an H100 in US-KS-2 and the instance is super slow. It has taken over ten minutes just to install Python dependencies. It's not just download speed (which is slow) but also CPU because after the downloads complete, processing the wheel installations is going very very slow. I was using A100 last week and this process went really fast.
```
root@7f041151afc9:/workspace/stanford-cs336-lmfs-assignment1-basics# uv run wandb login
Using CPython 3.13.5...