Setting a time limit for use
I can't figure out how to make fine tuning work
how to start with network volume through graphql api
api.runpod.io is down?
making pod a docker image
cant update, cant add loras to power lora loader and cant get text and clip files to show up
Can't get alleninstituteforai/olmocr running on any recommended pod.
"Recent NVIDIA GPU (tested on RTX 4090, L40S, A100, H100) with at least 15 GB of GPU RAM 30GB of free disk space"...
jupyter does not load in H200 XSM
Is runpod slower in the europe evening/ america mid day?
What's the easiest way to get a qwen-image pod?
How to install ollama (and download models) in to /workspace?
runpod/pytorch:2.8.0-py3.11-cuda12.8.1-cudnn-devel-ubuntu22.04 NOT RUN!
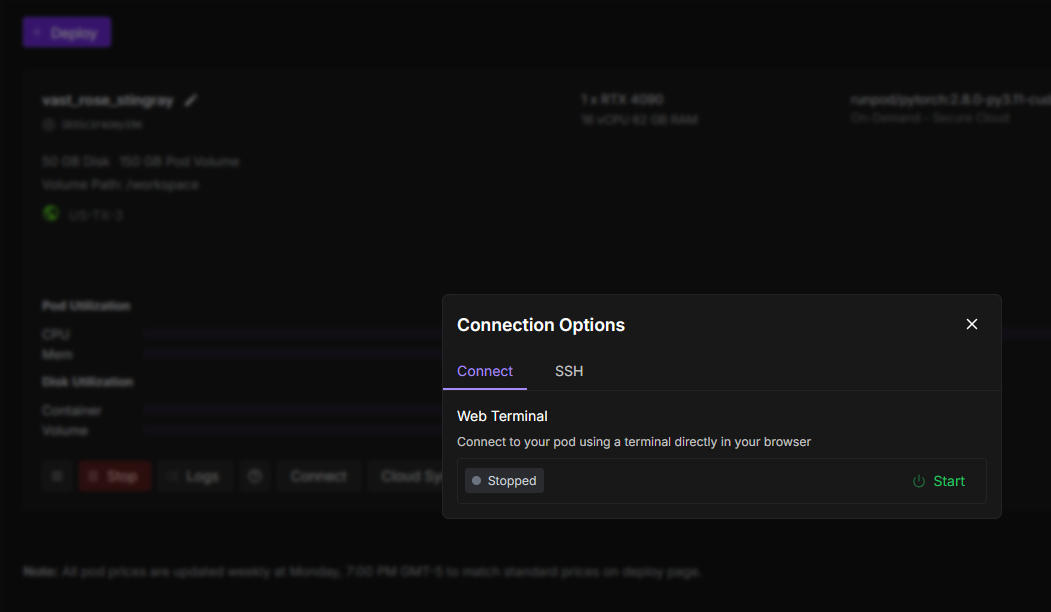
time out occur on pod
Can't start a pod anymore with graphql mutation without a networkVolumeId
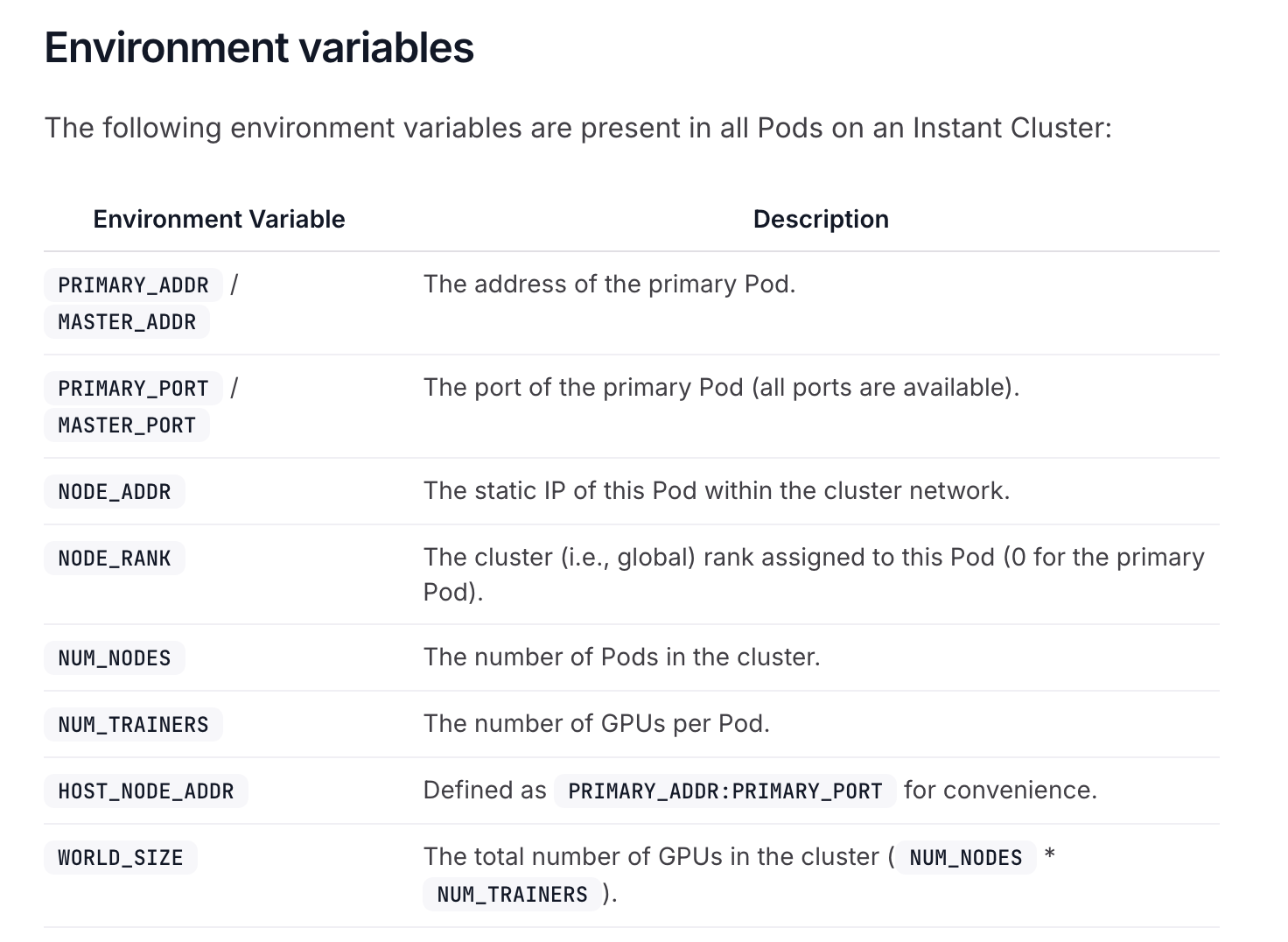
Instant Cluster DDP config not working
How to transfer 10 - 15 images from local to specific folder in Network volume
Migrating Network Disk Region
Dev permission access in a team setting.
GPU's are unavailable on pod.
c6ghnnsno6fkvu whatever pod id. I'll keep it for a day, to let you check it exactly.
Here's my script output:...