Charged overnight for terminated pad
I terminated my pod last night before going to bed, when I came back to runpod today my entire balance had gone and the session logs in the billing section showed that i spent $36 in one session which is more than 10 hours. The server I was using last night was also showing signs of connection issues, I'm pretty sure something went wrong here and the terminate command never made it to the pod even though when i clicked it i was sent back to the gpu selection screen.
Does pod has CUDA toolkit installed in host system?
I wonder if it's installed and might be shared with Docker system?
Full toolkit takes 10GB+ of space, so its a waste to include it into Docker image, however some libraries and python modules do need it, so I just thought that if its available in host system, maybe you can mount and symlink it into the container?...
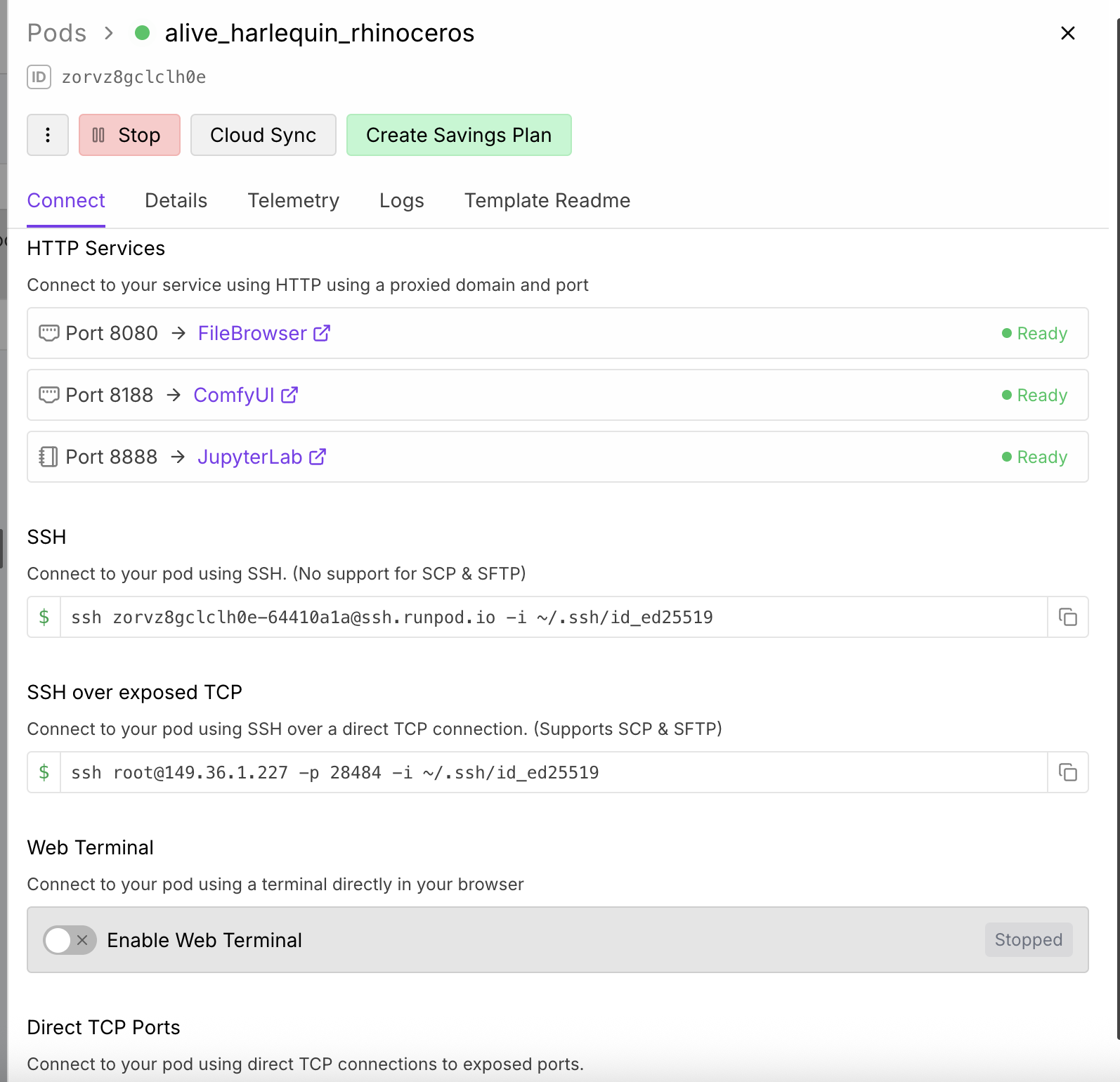
Runpod white screen, HTTP ERROR 404
I turn on the pod , everything looks good,
Both port showing ready
But once I try to enter its either white screen that doesnt load up or HTTP ERROR 404...
My POD Always Goes off
Hi,
We moved from serverless to Pod for making sure API returns response much faster. But now GPU goes off. Our Server won't make any API call to POD from 2AM-5AM. I have these questions.
1. When my GPU will go off ? I've chosen on-demand...

Hi, I am getting error with LORA training with PromptTunning
Issue: CUDA Out of Memory while loading model checkpoint.
Details:
Model: meta-llama/Llama-4-Scout-17B-16E-Instruct with 4-bit quantization (BitsAndBytesConfig)...
Network volume speed/latency issue
My tool can't load the GPU again because loading files from the network volume is terrible.
The current ticket ID: 24625
The issue is the same as:
https://contact.runpod.io/hc/en-us/requests/22382
https://contact.runpod.io/hc/en-us/requests/24185...
Solution:
The reason id here "net volumes can feel slow" https://discord.com/channels/912829806415085598/1424164384296538162/1426289858523168788
PODS have gone to SHIT
I see many users complaining and I hadn't experienced issues until this weekend. The Pod launches but Jupyter Lab never opens and if it does and you luanch ComfyUI the WHITE page of death just keeps loading...while CPU and memory are nowhere to be used.
Sort this crap out RUNPOD!!...
Solution:
Services are back to normal, I had a remote session with the support team and we verified everything is back to normal for Jupyter Lab and ComfyUI usage.

Not able to connect :(
Hey guys! I am new to runpod. Thanks in advance for all the help.
I tried to deploy pod with ssh and jupyter notebook, and it's been an hour and it's not getting connected. It says generating connection data and that's it blank logs and everything.
Has anyone faced this issue? If so, please help me through it. Thanks 🙂...
Jupter labs, port 8188, NOT WORKING
Since yesterday, its taking forever to connect to Jupter labs. If you're lucky enough to get into Jupter labs, then my python script to use port 8188 doesnt work. I CANNOT connect to port 8188. It was fine till 2 days ago. Pls fix
Runpod unusable
I've tried spinning up several pods, but the I/O is so slow, I can't run anything. ComfyUI takes 10 minutes to load the UI. Nothing is working.
Pods suddenly start with cuda 12.4 when 12.8 is requested
I have been starting pods via the python sdk and specified the cuda version that I need (12.8). This used to work well until a day or two ago. Today, when I start pods, I get this in the logs:
```
==========
== CUDA ==...
a trillion years to download some jpgs from jupyter
It's always a pain to download what I create in comfyui, in any pod, the 4th pod that I close and open and it works worse than a dead person

image generation extremy slow with RTX 5090
Basically my images with the same format are generated in 15 to 18 seconds, now it takes 40 seconds, a disgrace, same GPU as always, RTX 5090
POD ID: 2pbfz0u9uk836f
-...
Can't create fresh Official ComfyUI template Pod. CUDA issues.
I can't create a fresh new Official ComfyUI template pod. When I run a basic image generation I get :
CLIPTextEncode
CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect....
Network I/O extremely slow or throttled
Network I/O on all of my pods across different datacenters is extremely slow (50-200kbps). I have run a speedtest on the pods and it reports ~400Mb/s up+down speeds, however I am not seeing these speeds when talking to the API I have deployed on the pods, and downloading a 20MB file from the pod takes 3+ minutes. Why is this happening?
How to create a pod with private docker image?
I dont see any registry auth option when deploying a pod. I only see that for serverless

my pod is not working
why my pod is not working ? i wait for 3 hours with rtx 6000 pro to work the pod, i lose 6 dollars because of this error
File "/workspace/madapps/ComfyUI/comfy/model_management.py", line 237, in <module>
total_vram = get_total_memory(get_torch_device()) / (1024 * 1024)
^^^^^^^^^^^^^^^^^^...