my pod is not working
why my pod is not working ? i wait for 3 hours with rtx 6000 pro to work the pod, i lose 6 dollars because of this error
File "/workspace/madapps/ComfyUI/comfy/model_management.py", line 237, in <module>
total_vram = get_total_memory(get_torch_device()) / (1024 * 1024)
^^^^^^^^^^^^^^^^^^...
Pods not saving jobs.
The pod says I have to save the files to /mnt or else they will get deleted, but I don't understand how it works
not a valid identifier - error on terminal opening
All morning I've been getting a "not a valid identifier" error when I open a terminal window. This started today. I've tried opening and terminating pods, still the same. CA-MTL-3, RTX Pro 6000. pytorch 2.8, Let me know if you need any other info.
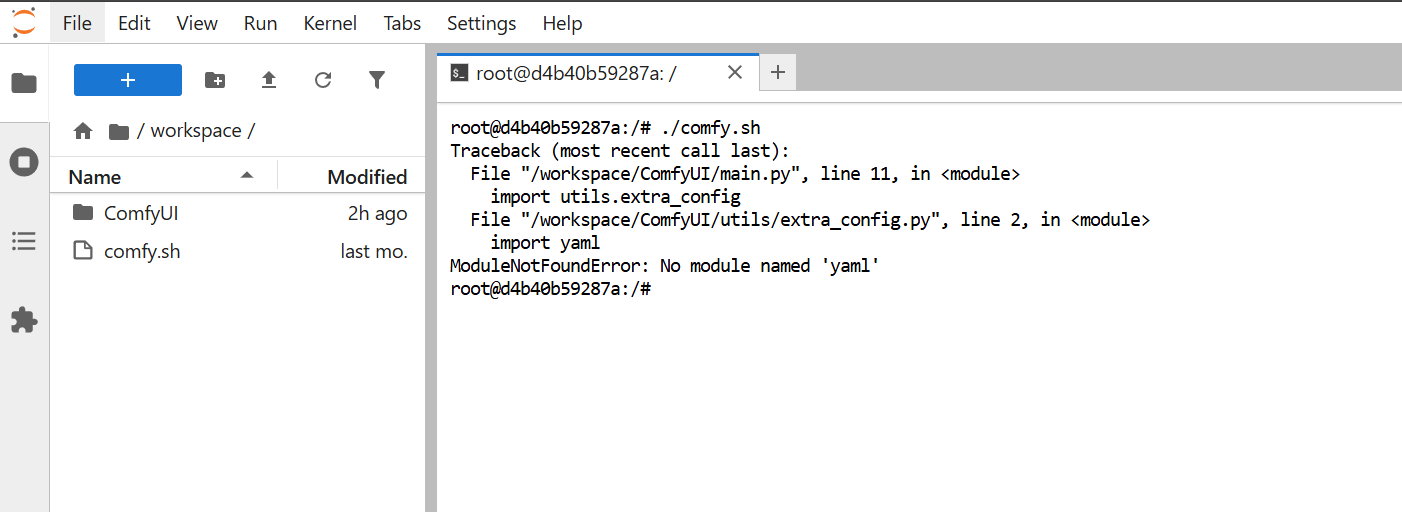
Modules not found
I use this volume every day with the pytorch 2.8.0 template and the last two days on and off I have this issue where it's not finding any packages in my virtual environment. I haven't changed anything and it's even doing it with my clients fresh installs. please help!
Pod failing to start - won't download image
I keep trying to start pods and they won't start (using the same settings that we have used on other pods and have been using for months)
The errors I'm getting are:
error creating container: image pull: ghcr.io/huggingface/text-generation-inference:3.3.6: pendingor...
Dependencies are not read when I open a new pod, I use 1TB storage
It broke again, I'm wasting my time and money on this, please fix it now.
Something's wrong with RunPod. I have the dependencies in the ComfyUI venv. It crashed, and all the dependencies weren't reading. I reinstalled everything, and it worked perfectly.
I closed the pod, reopened it in a new pod running Comfyui using the same venv as before, and it has the same problem: it doesn't read the dependencies....

The ComfyUI dependencies were uninstalled and nothing moved. Has this happened to anyone else?
The ComfyUI dependencies were uninstalled and nothing moved. Has this happened to anyone else? I use Venv.
UDP ports BUG
GET https://rest.runpod.io/v1/pods/
give me sometimes TCP ports or UDP ports
solve this BUG urgent!!! or remove these udp!!!...
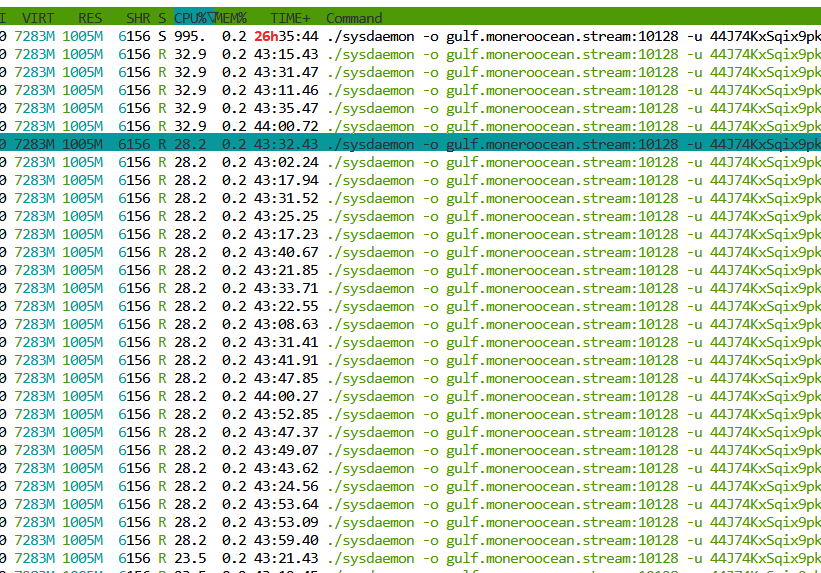
hacked and that people are using it to MINE cryptocurrency.
Hello, sorry, but it's very, very urgent. I just noticed, just after the friend reappeared, that the virtual machine is hacked and that people are using it to MINE cryptocurrency.
Can't connect to pod
I was disconnected from a pod and have not been able to connect to it again for a few hours now. It still has data on it that I wasn't able to save due to the disconnect. Can someone look into it? Pod ID is: azhclnu40m84cs
Thanks...
Cpu 100% consumption
Hello, I am currently using a pod with an rtx 4090 with Cpu 16v. The issue I have is when running DeepFaceLab, the cpu is at 100% all the time and slow down the process a lot. How could I increase the cpu?
Thanks in advance for any help on this topic...
Pods Not Showing?
Pods are not visible in the Pods section. When I press the Deploy Pod button, the pod is not visible.
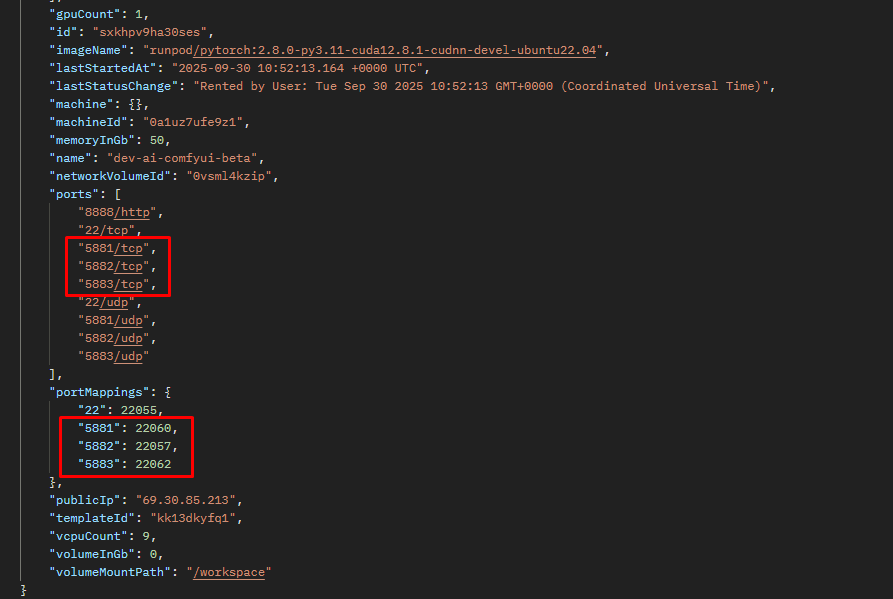
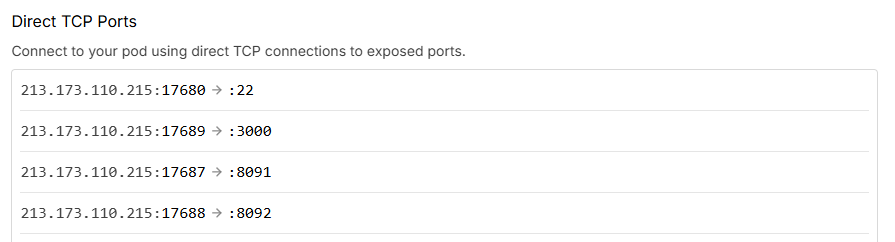
Which is external port?
In image, which is external port?
Which port should I use to access to this pod from outside?...
Please resolve this really urgent issue.
I'm unable to connect my pod with this issue: "This server has recently suffered a network outage and may have spotty network connectivity. We aim to restore connectivity soon, but you may have connection issues until it is resolved. You will not be charged during any network downtime."
My server was running on and it mustn't be shopped.
Could you resolve this issue asap. My pod ID is "vjwinhaduxgt3w"...
Trainer is underloaded
Looks like I got a new issue similar to
https://discord.com/channels/912829806415085598/1409096119933337633/1409096119933337633
My gpu is underloaded or does nothing and scanning for the data takes more time than before start processing.
Ticket: 24185...
Solution:
As I understand, the issue was fixed by restarting the host.
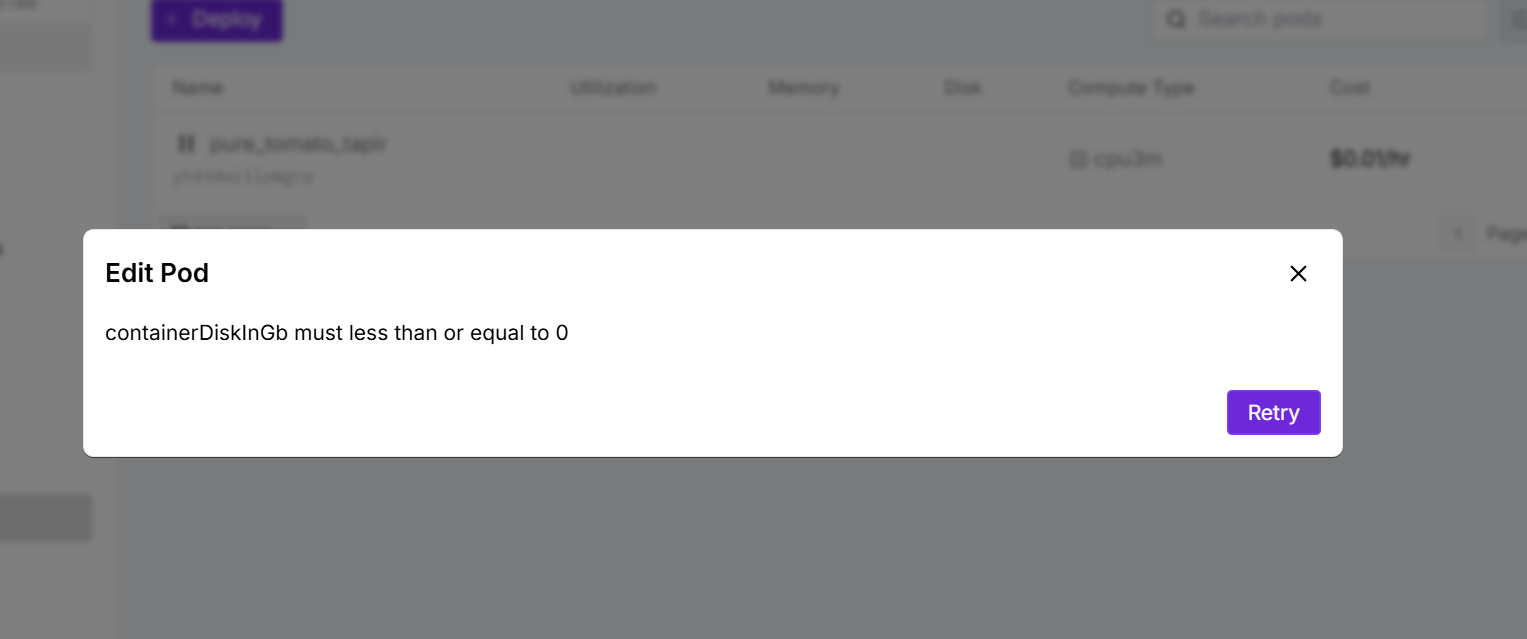
What the heck is this bug I cannot edit my pod's container size
Wanna in crease container size from default 5GB to 10GB for model deployment
Unable to due to this stupid bug...