Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
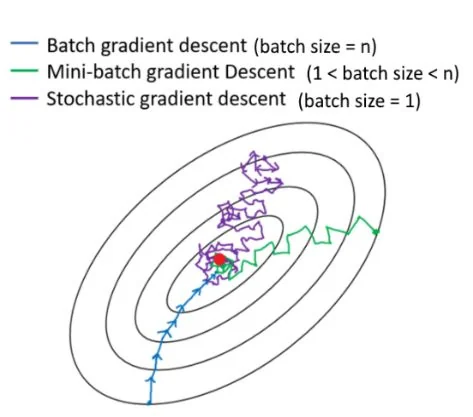
Meanwhile I used some extra settings, based on your conclusions, like offset noise to 0.07, image genertion to DEISMultistep, and testing to deterministic.
training lower rate for longer seems to raise the magnitude which makes the embedding not play well with other prompts, so it seems like 0.005 is about as good as it's gonna get. Wonder if i make the backgrounds transparent if that will allow the ai to focus on the model better
So far so good, but gradio froze, so I cannot track the progress. I assume if I close the window, the training will stop? I can see it running on the terminal, tough.
I just did this tutorial> https://www.youtube.com/watch?v=O01BrQwOd-Q and have this error > AssertionError: Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variable to disable this check
Our Discord : https://discord.gg/HbqgGaZVmr. This video I am showing how to downgrade CUDA and xformers version for proper training and I am showing how to do LoRA training with 8GB GPU. If I have been of assistance to you and you would like to show your support for my work, please consider becoming a patron on https://www.patreon.com/SECourse...
By the way Dr. Furkan, I noticed some changes on A1111 side too. Doing a fresh new install, everything works fine, but not Dreambooth. Dreambooth tab is not sowing in A1111 after the installtion. Just keeping you updated with my experience.
What is the best training method to train model certain object that is the same shape and similar form but it differs in decorations and filling. I have tried Dreambooth and Textual Inversion. With Dreambooth I used LORA for training and main problem is that when Im generating new things I can't specify how the object should look like because it is generated randomly and my prompts in most cases doesn't work, or work poorly. With textual inversion i feel like generated objects are poorer quality than loras. I have more control with the prompts but objects are generated in different perspecitve and in most cases not as a whole but zommed in.
I had simmilar problem with dreambooth not showing. I installed it by cloning extension from github and updating certain requirements. Also I installed python 3.10.6. With the older/newer it didn't work for me.
it never made sense until someone on reddit made the analogy of it's trying to make a statue out of a boulder. You want to start with a sledgehammer, and then move onto a chisel
Removes backgrounds from pictures. Extension for webui. - GitHub - AUTOMATIC1111/stable-diffusion-webui-rembg: Removes backgrounds from pictures. Extension for webui.
why try to do captioning and file words and all that when I can completely eliminate the background and focus on the subject which is what i want anyways
 F
F I
I Z
Z
 S
S F
F https://www.patreon.com/SECourse...
https://www.patreon.com/SECourse...
 E
E