 K
KHi, i'm having issues with setting up xformers with the A5000 GPU in SD Dreambooth
Whenever i click Generate Class Images i'm getting :
Exception generating concepts: No operator found for memory_efficient_attention_forward with inputs: query : shape=(1, 2, 1, 40) (torch.float32) key : shape=(1, 2, 1, 40) (torch.float32) value : shape=(1, 2, 1, 40) (torch.float32) attn_bias : p : 0.0 flshattF is not supported because: xFormers wasn't build with CUDA support dtype=torch.float32 (supported: {torch.bfloat16, torch.float16}) tritonflashattF is not supported because: xFormers wasn't build with CUDA support dtype=torch.float32 (supported: {torch.bfloat16, torch.float16}) triton is not available requires A100 GPU cutlassF is not supported because: xFormers wasn't build with CUDA support smallkF is not supported because: xFormers wasn't build with CUDA support max(query.shape[-1] != value.shape[-1]) > 32 unsupported embed per head: 40
I've set everything based on your youtube tutorial here https://www.youtube.com/watch?v=Bdl-jWR3Ukc&t=158s
Whenever i click Generate Class Images i'm getting :
Exception generating concepts: No operator found for memory_efficient_attention_forward with inputs: query : shape=(1, 2, 1, 40) (torch.float32) key : shape=(1, 2, 1, 40) (torch.float32) value : shape=(1, 2, 1, 40) (torch.float32) attn_bias : p : 0.0 flshattF is not supported because: xFormers wasn't build with CUDA support dtype=torch.float32 (supported: {torch.bfloat16, torch.float16}) tritonflashattF is not supported because: xFormers wasn't build with CUDA support dtype=torch.float32 (supported: {torch.bfloat16, torch.float16}) triton is not available requires A100 GPU cutlassF is not supported because: xFormers wasn't build with CUDA support smallkF is not supported because: xFormers wasn't build with CUDA support max(query.shape[-1] != value.shape[-1]) > 32 unsupported embed per head: 40
I've set everything based on your youtube tutorial here https://www.youtube.com/watch?v=Bdl-jWR3Ukc&t=158s

 F
Fgenerate class images with txt2img
Fmuch faster better

 G
GWith or without the --
 F
Fi think like this can you test?
Gdoes not work
Gwith the --
Fthere is no -- the command.
Gtrying without the --. I thought that is how the args are being separated
Gnope
Gdoes not work
Flet me show you
Fyou are writing incorrectly
Goh
GI see now
Gahahah
F G
GYup
GI was being stupid
Gfingers crossed this works
Gthen I will try train again with drambooth, set some checkpoints and then XYZ select from the checkpoints
Fi think dreambooth still wouldnt work on 8 gb :d
Fbut worth to try let me know
Gwill do
GI am just finding that runpod is harder than running it locally on windows
Gbut I don't get close to the image quality your SD is producing
KOn text2img im still getting the same error
NotImplementedError: No operator found for
Time taken: 1.82sTorch active/reserved: 2230/2246 MiB, Sys VRAM: 3577/24257 MiB (14.75%)
What could be wrong? I'm using SD 1.5.ckpt, and probably the text2img has nothing to do with Dreambooth
NotImplementedError: No operator found for
memory_efficient_attention_forward with inputs: query : shape=(2, 4096, 8, 40) (torch.float16) key : shape=(2, 4096, 8, 40) (torch.float16) value : shape=(2, 4096, 8, 40) (torch.float16) attn_bias : <class 'NoneType'> p : 0.0 cutlassF is not supported because: xFormers wasn't build with CUDA support flshattF is not supported because: xFormers wasn't build with CUDA support tritonflashattF is not supported because: xFormers wasn't build with CUDA support triton is not available requires A100 GPU smallkF is not supported because: xFormers wasn't build with CUDA support dtype=torch.float16 (supported: {torch.float32}) max(query.shape[-1] != value.shape[-1]) > 32 unsupported embed per head: 40Time taken: 1.82sTorch active/reserved: 2230/2246 MiB, Sys VRAM: 3577/24257 MiB (14.75%)
What could be wrong? I'm using SD 1.5.ckpt, and probably the text2img has nothing to do with Dreambooth
Kpython: 3.10.6 • torch: 1.13.1+cu117 • xformers: 0.0.17+6d62b0e.d20230322 • gradio: 3.16.2 • commit: a9fed7c3 • checkpoint: 4c86efd062
I'm currently new to this, apologies if i ask pretty basic questions.
I'm currently new to this, apologies if i ask pretty basic questions.
GNo luck with dreambooth on a 3070ti 8gig of vram
 Z
Zquick question, i can download LORA files from the civit.ai and not have to use prompts to invoke them, how can I do that with my lora model i'm training?
Zalso my models eyes are super blue and red, not sure why that is, i took the models photos, did face restoration, then used the face restored photos for my dataset
 G
GTrying to get dreambooth up and running on Runpod this monring and I can't seem to get it working again
Gdid something change ?
G F
Fok looks like that card not supporting
Finstall another xformers
Flet me tell you version
Ftry this
F0.0.17.dev476
Fpip install xformers== 0.0.17.dev476
KWill do it right now sir 
Fi see
 F
Fthat means auto loaded pt files
GI've updated the versions as well
G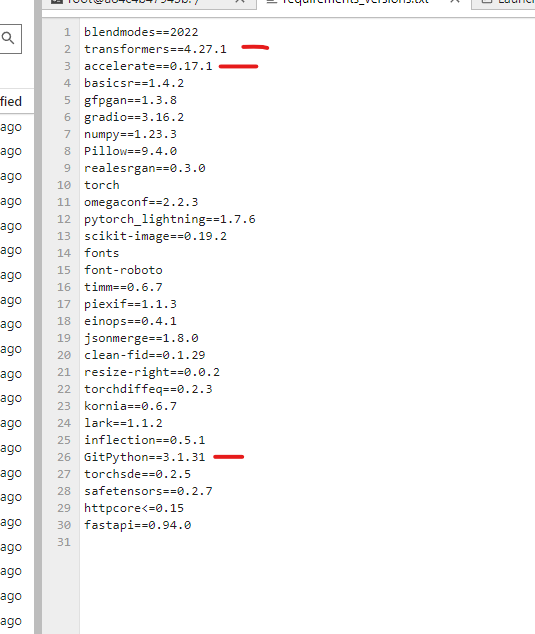 G
Gso I am not sure what is happening
Fi am also getting blue eyes usually :d i think related to prompts
Fyour xformers version probably not compatible
Factivate venv
Fdelete xformers