But also the Web UI needing an Internet connection, which wasn't necessary before the last update
But also the Web UI needing an Internet connection, which wasn't necessary before the last update
 F
F IIFFFIFFFFIFFI
IIFFFIFFFFIFFI SFF
SFF ZZZ
ZZZ S
S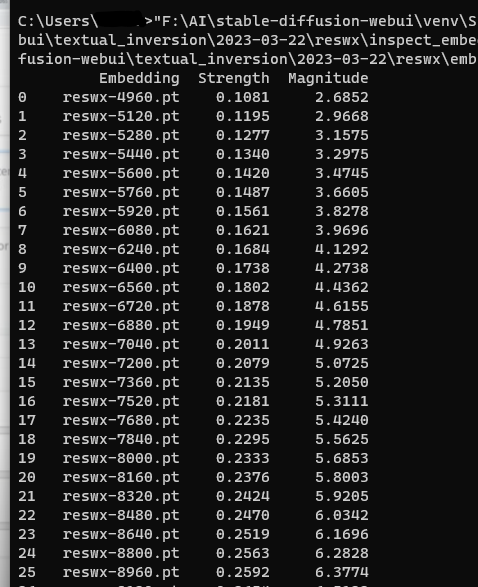 FZSZ
FZSZ S
S TST
TST B
B G
G TTTGGGG
TTTGGGG GG
GG Z
Z Z
Z
 EG
EG G
G G
G G
G K
K G
G





