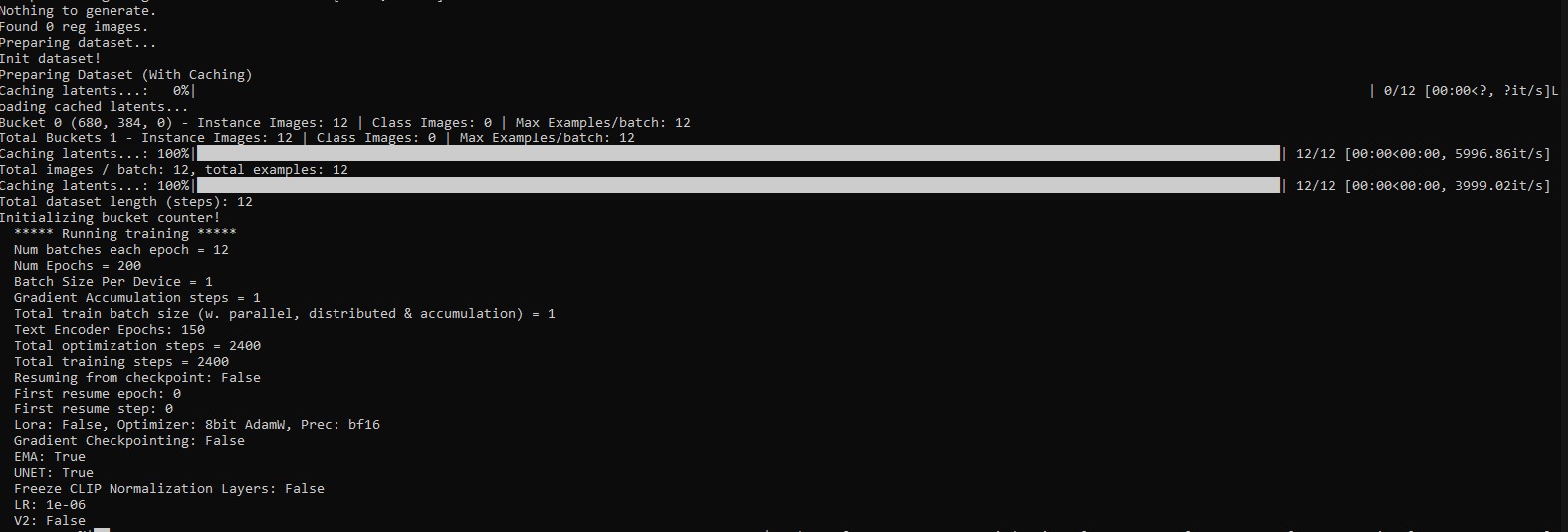
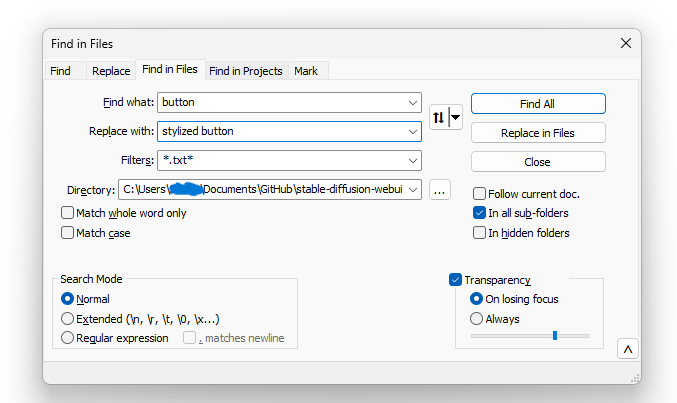
Yes precisely. I am doing Lora of recognisable fashion model person wearing recognisable fashion outfit. I need to be able to trigger the recognisable face and clothes, so it is rigid, and to do that I am using key tags in the caption to make the ai aware what is in the picture. I havent optimised yet for face, i am working on outfit to be faithfull to my studio original photo reference that I shot. But the point is, that BLIP captioning only creates the txt structure. The caption guess is pretty useless. But anyway, what i want is an Ai assistant to propagate the editing. So i decide, i need to change a term, say about the buttons, i need the button tags to change across all the txt files in the dataset. Do you know what I mean.