Hello everyone. I am Dr. Furkan Gözükara. PhD Computer Engineer. SECourses is a dedicated YouTube channel for the following topics : Tech, AI, News, Science, Robotics, Singularity, ComfyUI, SwarmUI, ML, Artificial Intelligence, Humanoid Robots, Wan 2.2, FLUX, Krea, Qwen Image, VLMs, Stable Diffusion
@Furkan Gözükara SECourses After a week of struggling to understand and to get things to run and not crash in the middle of training I have finally managed to get some acceptable results. Thanks to your tutorials and advice. Now on to style training...
Interesting, just watched the LoRA training guide, there's a lot of talk about Network Rank, it seems that lower network ranks seem to work well for some people, whereas the higher ranks seem preferable in other instances
@Furkan Gözükara SECourses Doctor G, I want to follow along with your latest video with the Kohya LoRA Stable Diffusion training. I'm on GNU/Linux, will that make a difference? I don't think I'd use Visual Studio for example. Thank you for all of the work you put into every one of your videos!!!
Hey! Watching your new Lora video now. Although, I thought using dream booth extension for Lora training was better? Should I continue using dream booth, or Kohya gui?
@Furkan Gözükara SECourses Odd, I'm following along with the Kohya LoRA video and I don't seem to have the same interface? I don't see the Network Rank and Network Alpha and I don't see anything about LORA on the interface? I don't know what I could have done wrong.
\stable-diffusion-webui\venv\lib\site-packages\torchvision\transforms\functional_tensor.py:5: UserWarning: The torchvision.transforms.functional_tensor module is deprecated in 0.15 and will be removed in 0.17. Please don't rely on it. You probably just need to use APIs in torchvision.transforms.functional or in torchvision.transforms.v2.functional. ?
@Furkan Gözükara SECourses thank you for latest video about Lora. I am trying to generate reg images, but they all look like sketches, not realistic portraits. I am using same model and VAE in video. Any advice?
Any opinions on captioning for face TI training? Do you structure your captions like "Photograph of a man, wearing a red shirt, white background" - Or do you tend to just have a single string without commas?
yeah, not very useful until then. I have a feeling its gonna have that same vibe that vhs tapes give when you watch them. Instantly recognizable that its stable diffusion.
I have a quick question. For Lora training. I’m wondering why ohwx has to be used as instance token? If we’re training a person, can’t we just use their first and last name as the instance token, followed by the class token? Or does that not work as well ? (For instance prompt and class prompt I use file words)
 F
F Z
Z A
A
 J
J W
W I
I D
D E
E P
P T
T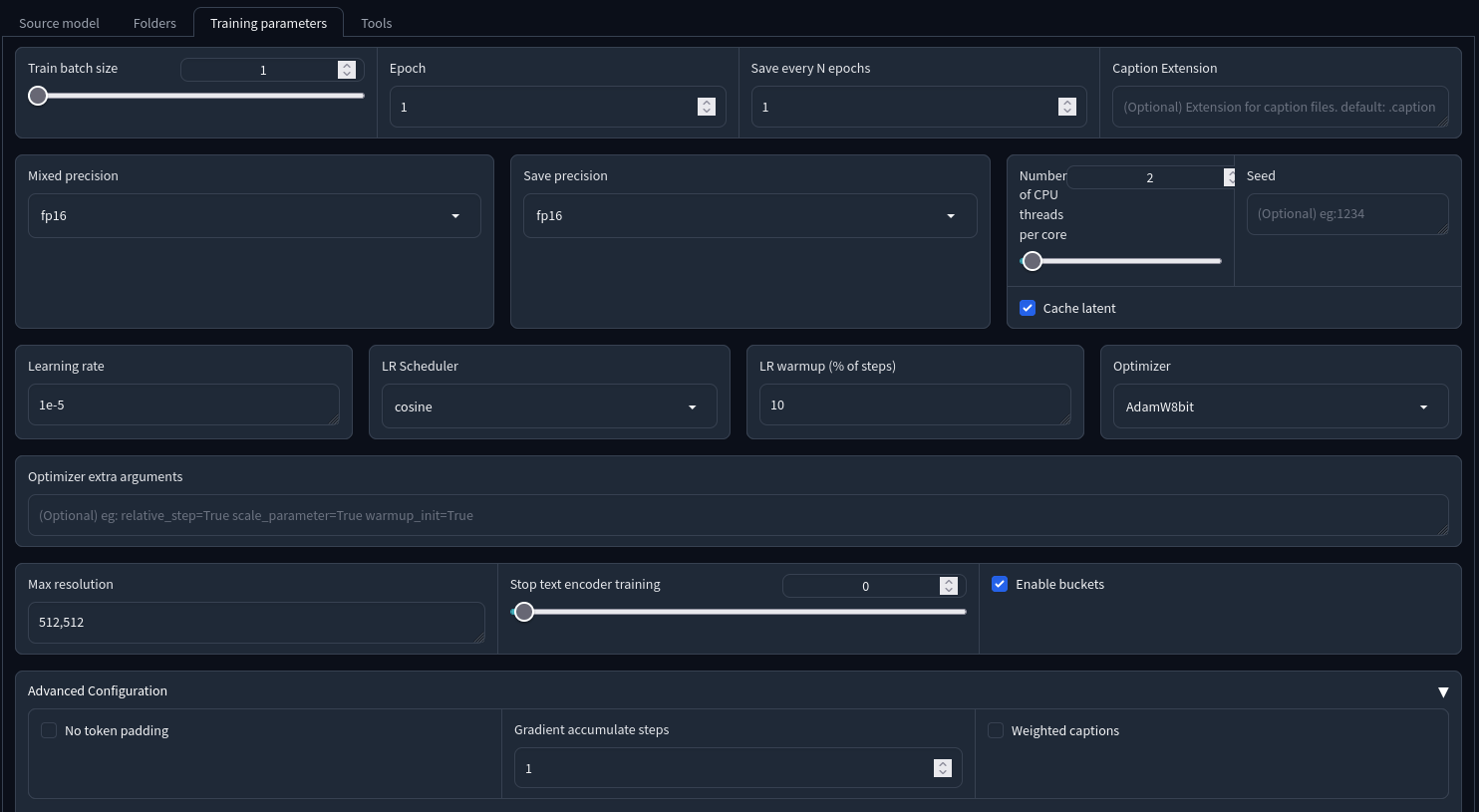
 G
G
 L
L M
M





